[Kaggle Gen AI] Day 5 - 생성형 AI 배포와 거버넌스: 최종 사용자 시스템에서 자율 에이전트까지 🚀
![[Kaggle Gen AI] Day 5 - 생성형 AI 배포와 거버넌스: 최종 사용자 시스템에서 자율 에이전트까지 🚀](/assets/images/20250402/day5_1.png)
지난 글 생성형 AI 시스템의 성능을 어떻게 평가할 수 있는지 살펴봤다.
정성적 평가, 자동화된 LLM 기반 평가, 사용자 피드백까지 다양한 접근을 통해 실제 사용에 앞서 시스템의 품질을 진단하는 방법들이 있었는데,
이제 시스템이 준비되었다면, 다음 단계는 바로 세상에 내놓는 일인 배포와 운영 이다.
생성형 AI 시스템을 실제 환경에 배포하고, 운영하면서 발생하는 다양한 이슈들을 어떻게 관리할 수 있는지에 대해 알아보겠다.
- 최종 사용자용 시스템을 배포할 때 고려해야 할 점부터,
- 대규모 파운데이션 모델의 배포,
- 운영 중 발생할 수 있는 데이터 드리프트와 성능 저하 탐지,
- 시스템 전체를 감싸는 모니터링, 로깅, 거버넌스 체계,
- 마지막으로 생성형 AI의 프론티어라고 할 수 있는 에이전트 운영까지 간단히 다룬다!
참고로, 이 게시물은 Kaggle Gen AI 5-day intensive course 마지막 날인 Day 5이면서 Day 5의 마지막 게시물이다!! 야호
🚀 배포: 생성형 AI 시스템을 실제 환경에 내놓기
지금까지 시스템을 구축했고, 평가도 마쳤다.
이제 이걸 세상에 내놓을 배포 (deployment) 단계가 되었는데, 생상 환경에서 생성형 AI 시스템을 운영하는 것은 상당히 복잡한 작업이라고 한다.
그냥 모델 하나만을 배포하는 문제가 아니라 프롬프트, 모델, 어댑터 계층 (adapter layers), 외부 데이터 소스 등 여러가지 요소가 모여 하나의 시스템을 이룬다.
여기서는
- 생성형 AI 시스템 배포 (generative AI system),
- 최종 사용자용 완성 솔루션 배포 (complete enduser solution),
- 그리고 파운데이션 모델 자체의 배포 (foundation model itself)
를 구분하는데,
파운데이션 모델 자체를 배포하는 것은 모델을 쉽게 접근할 수 있게 하는 데 초점이 맞춰져 있다.
제일 먼저, 최종 사용자용 시스템 (enduser system)을 배포할 때 특별히 고려해야 할 점들은 무엇일까?
팟캐스트에서는 두 가지의 예시를 보여준다:
- 버전 관리 (version control)
- 프롬프트 템플릿, 체인 정의, 사용하는 외부 데이터셋 등 모든 것의 변경 이력을 추적해야 한다.
- 특히 외부 데이터셋을 관리하기 위해 BigQuery, AlloyDB, Vertex Feature Store같은 솔루션을 활용할 수 있다.
- 이제는 단순한 플랫 파일(flat files)이나 로컬 DB에만 의존하는 시대가 아니다!
- CI/CD; 지속적 통합 및 지속적 배포
- 모든 코드 체인은 병합되기 전에 자동으로 테스트되어야 하고,
- 테스트가 끝난 코드를 실제 운영 환경에 안전하게 옮기기 위한 신뢰성 높은 파이프라인이 필요하다.
하지만 생성형 AI만의 CI/CD는 과제들이 있다:
- 포괄적인 테스트 케이스 만드는 것의 어려움 (difficulty of generating comprehensive test cases)
- 결과의 재현 가능성 문제 (potential for reproducibility issues)
생성형 모델은 매우매우 다양한 출력을 생성할 수 있고, 출력이 비결정적 (non-deterministic)일 수도 있기 때문이다.
하지만 그렇다고 CI/CI가 불가능한 것은 아니다. 생성형 AI에 맞춰 접근 방법을 조정하면 충분히 가능하다.
🛠️ 운영: 파운데이션 모델 배포와 시스템 모니터링
다음으로, 파운데이션 모델 자체를 배포할 때 고려해야 할 점이다.
파운데이션 모델은 규모가 엄청나게 크기 때문에 이 모델을 운용하기 위해서는 엄청난 수준의 컴퓨팅 자원과 저장 공간이 필요하다.
또한, GPU나 TPU같은 하드웨어뿐 아니라 BigQuery나 클라우드 스토리지 같은 확장 가능한 데이터 저장 솔루션(scalable data storage solutions)도 고려해야 하는데,
모델 압축 (model compression) 같은 기법을 통해 모델의 크기를 줄이고 관리하기 쉽게 만드는 방법도 있다.
이제 생성형 AI 시스템을 배포했다고 가정해 보자.
이 시스템이 실제 환경에서 계속해서 잘 동작하는지 확인해야 하는데, 바로 여기서
- 로깅 (logging)
- 모니터링 (monitoring)
이 중요해진다.
이 작업들도 생성형 AI가 끼면 만만치 않다.
이런 시스템들은 종종 여러 컴포넌트를 체인 형태로 연결해서 동작하기 때문이다.
그래서 엔드 투 엔드 (end-to-end) 로깅과 모니터링이 필요하다.
그리고 시스템 전체에 걸쳐 데이터의 흐름을 추적할 수 있어야 하며, 문제가 생겼을 때 어디서 문제가 시작되었는지 파악할 수 있어야 한다.
그래서 계보 추적 (lineage tracking)이 매우 중요해진다.
요런 맥락에서 스큐 감지 (skew detection)와 드리프트 감지 (drift detection)도 나오는데,
- 스큐 감지 (skew detection)
- 시스템을 평가할 때 사용한 입력 데이터의 분포와 실제 운영환경에서 들어오는 데이터의 분포를 비교하는 것이다.
- 만약 이 두 개의 분포가 점점 달라진다면, 지금 시스템이 현실의 데이터를 잘 다루지 못할 위험이 있다는 신호가 될 수 있다.
- 드리프트 감지 (drift detection)
- 시간에 따라 입력 데이터가 어떻게 변하는지 살펴보는 것이다.
- 즉, 사용자 행동이 어떻게 진화하고 있는지를 이해하는 것이다.
- 예를 들어, 새로운 질문 유형, 새로운 주제, 새로운 의도가 등장하는지 모니터링하는 것 등등이 있다.
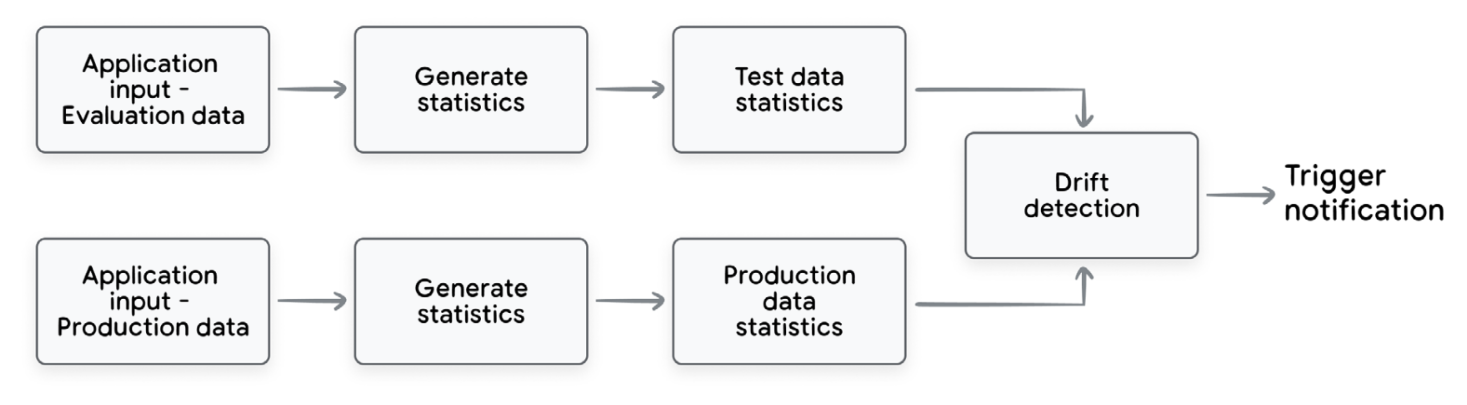 Drift/skew detection process overview
Drift/skew detection process overview
그렇다면 얘네를 실제로 어떻게 측정할까? 데이터의 종류에 따라 방법이 달라진다.
텍스트라면,
- 임베딩 (embedding)
- 거리 (distances)
- 어휘 변화 (vocabulary changes)
- 통계 분석 (statistical methods)
같은 다양한 지표를 활용해 데이터의 분포가 바뀌었는지를 탐지할 수 있다.
멀티모달 (multimodal) 모델의 경우에는,
- 프롬프트 정렬 (prompt alignment): 지금 사용하는 프롬프트가 여전히 효과적인지,
- 조직 정책 정렬 (policy alignment): 시스템 출력이 조직의 정책에 맞는지,
이런 점들은 모두 중요한 고려 사항이다.
또한, 팟캐스트에서는 지속적 평가 (continuous evaluation)의 중요성도 말하면서, 운영 환경에서 나오는 데이터를 계속 수집하고 (capturing production outputs), 자동으로 평가 작업 (running evaluation tasks)을 돌려야 한다고 한다.
그리고 당근 알림 (alerting)도 설정해서 문제가 생겼을 때 사용자가 불평하기 전에 먼저 알아차릴 수 있어야 한다.
마지막으로, 트래이싱 (tracing)도 중요한 로깅 기법이다.
트래이싱이란 시스템 내부에서 일어나는 이벤트의 흐름을 기록하는 것인데, 이렇게 하면 각 컴포넌트가 어떻게 상호작용하는지를 이해할 수 있다.
디버깅을 하거나 의사결정 과정을 추적할 때 특히 유용하다.
🧭 거버넌스: 신뢰할 수 있는 생성형 AI 운영을 위한 관리 체계
이제 모니터링 데이터가 들어오기 시작한다고 치면! 이제 중요한 건, 이 데이터를 잘 해석하고 시스템이 제대로 작동하는지 확인하는 것이다.
바로 이 지점에서 거버넌스 (governance)가 필요해진다.
MLOps 거버넌스란, 머신러닝 전체 라이프사이클에 걸쳐 통제, 책임, 투명성 (control, accountability, transparency)을 보장하기 위한 실천과 정책을 말한다.
그리고 이 모든 것들을 생성형 AI에 적용할 때, 원칙들은 더 중요해진다. 단순히 모델만 관리하는 것이 아닌, 프롬프트 체인, 데이터 등 시스템 전체를 포괄적으로 관리해야 한다.
팟캐스트에서는 기존의 MLOps, DevOps 관행이 여기에도 그래도 적용된다고 강조한다.
그래서 우리는 이러한 것들을 관리해야 한다:
- 데이터 (data)
- 모델 (models)
- 코드 (code)
이 모든 것이 관리 대상이다.
🤖 AgentOps: 생성형 AI의 미래, 에이전트 운영
여기까지 정말 많은 내용을 다뤘다.
생성형 AI 시스템을 탐색-개발-평가-배포-모니터링-거버넌스 (discovering-developing-evaluating-deploying-monitoring-governing) 하는 전 과정을 훑어봤다.
그런데 추가로, 또 하나의 영역을 소개하고 있다: 바로 이런 원칙을 에이전트(agent)에까지 확장하는 것!
팟캐스트에서는 이걸 AgentOps라고 하며, 이는 생성형 AI의 다음 단계(frontier)와 같다고 소개했다.
이건 단순히 출력을 생성하는 것을 넘어서, 실제로 현실과 상호작용하며 스스로 의사결정을 내리는 시스템을 만드는 이야기까지 나아가게 된다.
에이전트는 기술적으로 획기적인 도약을 의미하며, 이전에는 불가능했던 복잡한 업무를 자동화하고, 난제를 해결할 수 있는 잠재력을 가지고 있다.
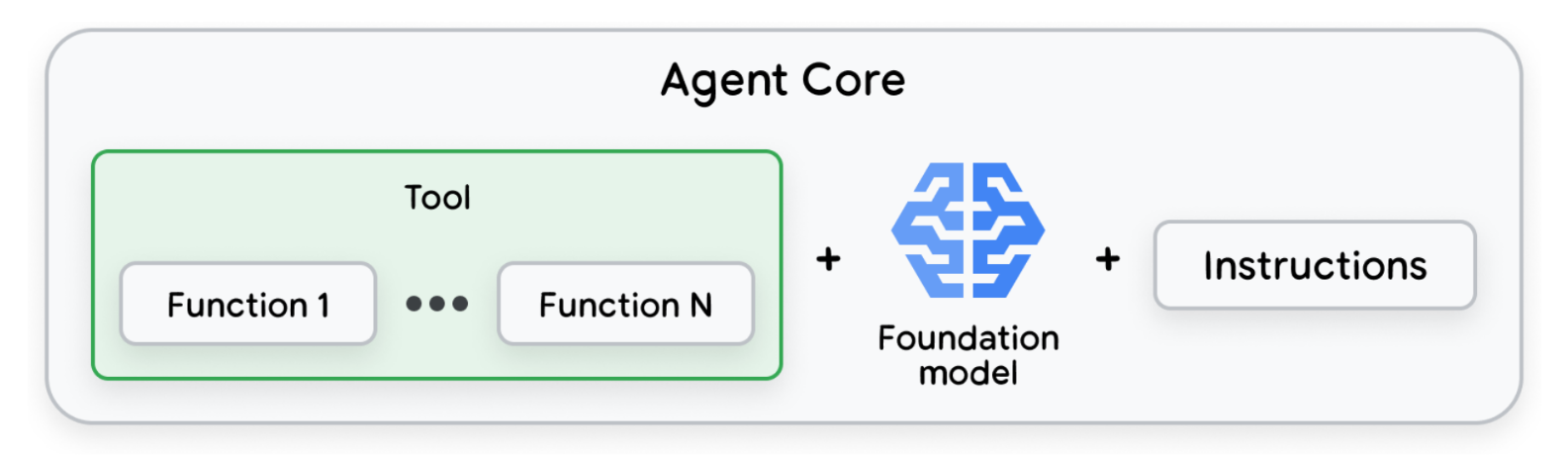 Agent Core: Tools, model, and instruction prompt
Agent Core: Tools, model, and instruction prompt
하지만 동시에, MLOps 관점에서 완전히 새로운 과제들도 등장한다.
에이전트 운영은 기존의 MLOps와 무엇이 다를까?
가장 큰 차이점 중 하나는,
- 이제 훨씬 더 자율적인 시스템을 다루게 된다는 것이다.
- 에이전트는 사람의 직접적인 개입 없이 스스로 의사결정을 내리고 행동할 수 있다.
- 그래서 이런 시스템을 신뢰하려면, 아주 견고한 거버넌스·모니터링·통제 프레임워크가 필요하다.
또 다른 도전 과제는,
- 에이전트가 다양한 외부 시스템과 데이터 소스와 상호작용한다는 점이다.
- 따라서 그런 상호작용을 관리하고 보안을 보장할 수 있는 강력한 메커니즘이 필요하다.
So it’s like managing a team of highly skilled but potentially unpredictable employees.
그래서 이건 마치 실력은 뛰어나지만 예측 불가능할 수도 있는 직원들로 이루어진 팀을 관리하는 것과 같다.
- 따라서 팀원들에게 명확한 목표와 경계를 설정해야 하고,
- 성과를 모니터링하고,
- 문제가 생기면 개입할 수 있어야 한다.
팟캐스트에서는 이런 과제들을 해결하기 위한 다양한 개념과 도구를 소개한다.
- 툴 오케스트레이션 (tool orchestration)
- 에이전트가 세상과 상호작용할 때 사용하는 여러 도구들을 일관되게 관리하는 일이다.
- 툴 레지스트리 (tool registry)
- 모든 툴을 관리하고 탐색할 수 있는 중앙 카탈로그 같은 것으로,
- 에이전트가 아무 툴이나 마음대로 쓰게 두는 대신, 신뢰할 수 있고 검증된 도구들만 사용할 수 있도록 제한할 수 있다.
- 이 덕분에 일관성 (consistency), 보안 (security), 감사 가능성 (auditability)이 유지된다.
다음으로, 대규모 운영에서 어떤 도구를 에이전트에게 제공할지를 결정하는 전략 몇 가지가 있다.
- 제너럴리스트 접근 (Generalist approach): 모든 도구를 개방
- 스페셜리스트 접근 (Specialist approach): 특정 작업에 필요한 제한된 도구만 제공
- 동적 접근 (Dynamic approach): 에이전트가 런타임에 툴 레지스트리에서 가장 적절한 도구를 선택하게 하는 방식
이건 마치 집 수리할 때 종합 시공접자 (General Contractor)를 고용할지, 전문 시공업자 (Specialist)를 고용할 지 결정하는 것과 비슷하다.
So it’s like deciding whether to hire a general contractor or a specialist for a home renovation project
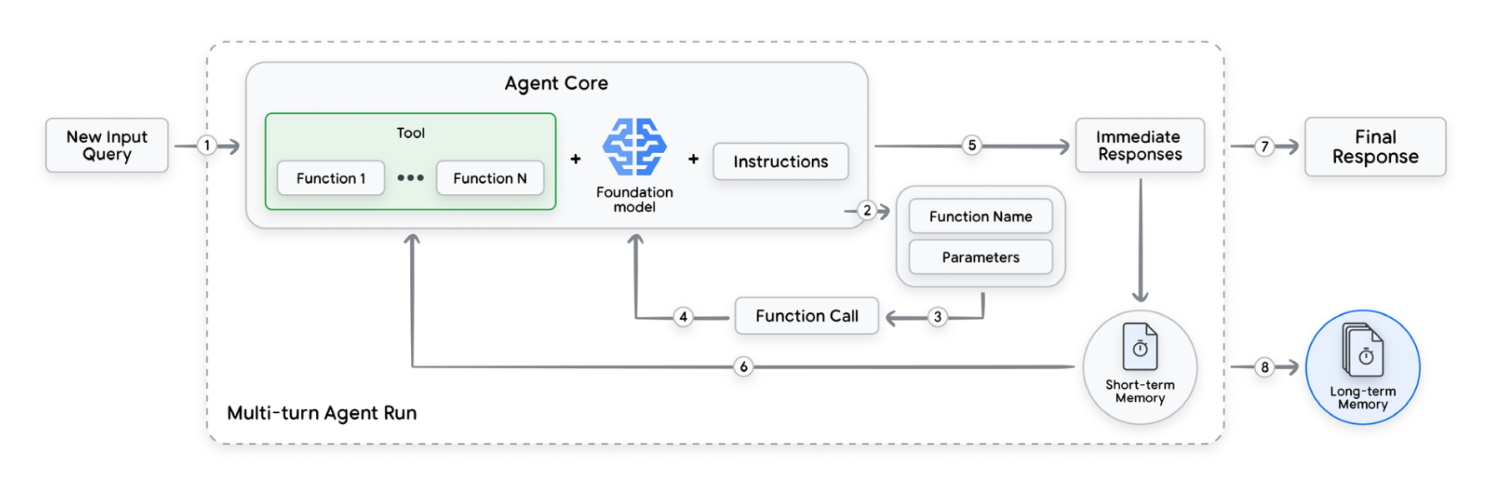 Multi-turn interaction of an agent with tools and memory until the final response
Multi-turn interaction of an agent with tools and memory until the final response
또 하나의 중요한 과제는, 에이전트를 평가하고 최적화 (evaluating and optimizing)하는 것이다.
에이전트가 잘 작동하는지는 어떻게 알 수 있을까? 그 성능을 어떻게 측정할까?
팟캐스트에서는 에이전트를 평가하기 위한 5단계 프로세스를 소개한다.
이 프로세스는 툴 유닛 테스트 (tool unit testing)부터 운영 지표 평가 (operational metric evaluation)으로 마무리된다고 한다.
추가로, 가시성 (observability)와 설명가능성 (explainability)의 중요성도 이야기한다.
에이전트가 무엇을 하고 있는지, 왜 그렇게 하는지, 어떻게 의사결정을 내리는지를 이해할 수 있어야 한다. 이건 결국 신뢰 (trust)의 문제로 귀결되는데, 에이전트를 신뢰하려면 그 행동을 이해할 수 있어야 한다.
You need to be able to trust the agent, which means you need to understand it.
그리고 팟캐스트에서는 단기 기억 (short-term memory), 즉 대화 히스토리와 장기 기억 (long-term memory), 즉 과거 상호작용이 맥락 제공과 추적 가능성 위해 중요하다고 말한다.
마지막으로, 에이전트를 프로덕션에 배포하는 과정을 단계별로 설명하는데, 이 과정에는:
- 견고한 CI/CD 파이프라인 (robust CI/CD pipeline)
- 자동화된 도구 등록 (automated tool registration)
- 지속적 모니터링 (ontinuous monitoring)
- 반복적인 개선 루프 (iterative improvement loop)
이 모든 것이 포함된다.
💭 오늘 챙겨간 것들
- 생성형 AI 시스템은 단순히 모델만 배포하는 게 아니라 프롬프트, 체인, 외부 데이터 등 다양한 구성 요소의 통합이 필요하다.
- 최종 사용자 시스템의 배포에서는 프롬프트 버전 관리, 외부 데이터 소스 관리, CI/CD 자동화가 핵심이다.
- 운영 단계에서는 로깅·모니터링·트래이싱·계보 추적이 필수이며, 드리프트/스큐 감지를 통해 성능 저하를 조기에 탐지해야 한다.
- 거버넌스는 MLOps 원칙을 확장해 데이터, 모델, 코드, 프롬프트 전반에 대한 통제와 책임, 투명성을 확보하는 일이다.
- 에이전트 운영 (AgentOps)은 생성형 AI의 프론티어로, 자율적 행동을 하는 시스템을 안전하게 배포하고 관리하기 위한 툴 오케스트레이션, 메모리 관리, 평가 체계가 필요하다.
모든 단계에서 중요한 것은 지속적 모니터링, 자동화된 테스트, 반복적인 개선 루프를 갖춘 신뢰 가능한 시스템 운영 체계를 마련하는 것!
여기까지가 Kaggle의 Gen-AI 5-day intensive course 내용의 끝이다!
백서까지 정리하면 더 풍부하고 자세한 내용이었겠지만, 팟캐스트만으로도 충분히 많고 방대해서 이번에는 개념 정리를 팟캐스트 중심으로만 진행했다. 백서는 필요한 경우 참고하는 정도로 활용했다. (아직까지는 영어 읽기보다 듣기가 편함)
이 프로그램을 통해 LLM의 기반이 되는 트랜스포머 아키텍처부터 생성형 AI를 활용한 서비스 운영과 활용까지 정말 다양한 개념을 다뤄볼 수 있었다.
실습도 하나하나 정리하며 코드를 올리면 완벽하겠지만,,,! 일단은 정해진 순서 없이, 내가 당장 필요하다고 느끼는 부분부터 코드로 확인해보고, 기회가 될 때 여유롭게 정리해 올릴 예정이다.
재밌네효 캐글짱!