[Kaggle Gen AI] Day 5 - 생성형 AI 개발과 운영의 핵심 단계: 체이닝, 튜닝, 데이터, 평가 🚀
![[Kaggle Gen AI] Day 5 - 생성형 AI 개발과 운영의 핵심 단계: 체이닝, 튜닝, 데이터, 평가 🚀](/assets/images/20250402/day5_1.png)
지난 글생성형 AI를 현실에서 ‘진짜 쓰이는’ 시스템으로 만들기 위한 여러 전략을 살펴봤다.
그 중에서도 생성형 AI 시스템의 생애주기 5단계 중 앞의 두 가지, 개발 그리고 탐색 및 실험 단계들을 정리했다.
이번 글에서는 그 모든 흐름을 따라온 시스템을 어떻게 평가 (evaluation)할 것인가라는 주제로 넘어가려고 한다.
모델이 잘 작동하는지를 확인하고, 그 기준을 어떻게 정의하고 자동화할 수 있을지 살펴보겠다.
🧩 복잡한 문제를 다룰 때 필요한 전략: 체이닝과 증강
여기까지 프롬프트로 여러 가지 실험을 통해 어느 정도 모델이 원하는 대로 작동하게 만드는 방법을 익혔다고 했을 때, 상황이 더 복잡해지면 어떻게 해야 할까?
이 단계에서 체이닝과 증강 (Chain and Augment)에 대해 이야기한다.
아무리 강력한 대형 언어 모델(LLM)이라도 한계가 있다.
- 환각 (hallucination) 현상
- 아주 최신의 정보에 접근하는 데 어려움을 겪을 수 있고, 그냥 잘못된 출력을 만들어낼 때도 있다.
- 그리고 여러 단계를 거치는 복잡한 추론이 필요한 작업에는, 단일 prompted model component만으로는 부족할 수 있다.
바로 이런 상황에서 체이닝 (Chaining)이 필요하다.
체이닝이란, 여러 개의 prompted model component를 연결하고, 외부 API 호출이나 커스텀 로직을 결합해서 보다 복잡한 문제를 함께 해결하도록 만드는 방식이다.
아래 그림을 보면 prompted model, 외부 데이터 소스, 조건부 로직 같은 다양한 컴포넌트들이 서로 연결되어있는 걸 알 수 있다.
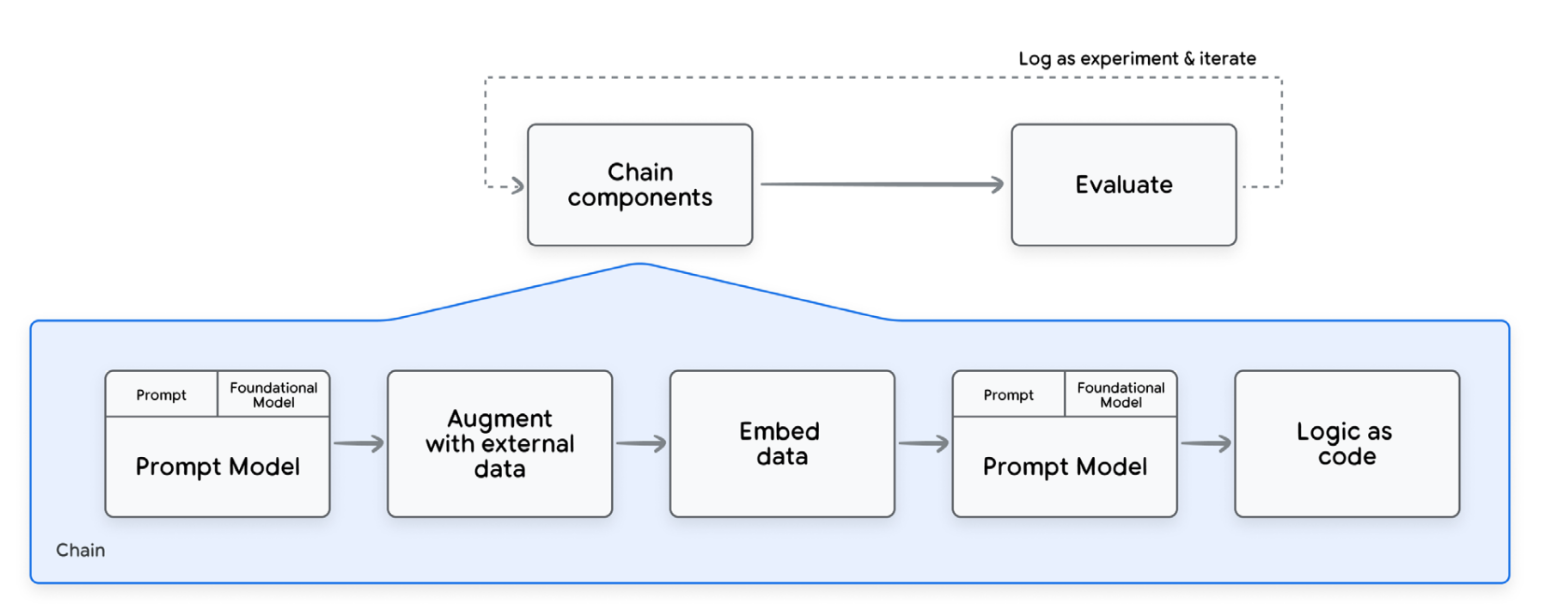 Components of a chain and relative development process
Components of a chain and relative development process
팟캐스트에서는 체이닝에서 자주 쓰이는 두 가지 강력한 패턴이 있는데, 바로: RAG (Retrieval Augmented Generation)과 에이전트 (Agents)이다.
- RAG (Retrieval Augmented Generation)
- RAG는 모델의 최신성 문제와 환각 문제를 해결하는 방법이다.
- 모델을 모든 데이터로 학습시키는 대신, 외부 데이터베이스에서 필요한 지식을 가져와서 모델에 실시간으로 보충하는 것이다.
- 쿼리가 들어오는 순간, 관련 정보를 모델에 주입하는 방식이다.
- 이 방식은 모델의 응답을 실제 사실에 기반하도록 도와주면서, 환각 현상을 방지하는 데 도움이 된다.
So it’s like giving the model a cheat sheet.
- 에이전트
- 에이전트는 RAG보다 훨씬 더 진화된 개념이다.
- 에이전트는 LLM을 일종의 두뇌처럼 사용하며, 결정을 내리는 중심부로서 여러 도구와 상호작용할 수 있다.
- 도구에는 RAG 시스템, 내부 API, 심지어는 다른 에이전트까지 포함될 수 있다.
- 에이전트는 처리 중인 정보를 바탕으로 실제 행동을 취할 수도 있다.
So it’s like giving the model hands and feet basically.
RAG와 에이전트를 결합해 더 강력한 시스템을 만드는 사례도 알려주는데, 이렇게 생각할 수도 있을 것이다:
“AI 컴포넌트를 체이닝하는 데 뭐 새로울 게 있나? 추천 엔진도 예전부터 그렇게 했잖아” (“Chaining different AI components together isn’t that old news. We’ve had recommendation engines doing that for years.”)
하지만 생성형 AI 체인에는 중요한 차이가 있다: 바로 입력 데이터의 본질이다.
전통적인 체인에서는 각 컴포넌트에 들어가는 입력의 분포를 비교적 명확히 정의할 수 있었지만, 생성형 AI 체인에서는 언어라는 본질적으로 혼란스러운 (inherently messy) 데이터를 다루기 때문에, 사전에 입력 분포를 명확히 규정하기 어렵다.
이 때문에 개발과 실험에 접근하는 방식이 달라진다.
개별 모델을 따로따로 반복 실험하는 것이 아니라, 전체 체인을 하나의 단위로 보고 실험해야 한다.
각 부품이 서로에게 영향을 미치기 때문에 마치 기계를 조립하는 것과 같다.
So it’s like you’re building a machine and each component affects the other components.
평가 (evaluation)도 전체적으로 이루어져야 한다.
체인 전체의 성능은 컴포넌트 간의 상호작용에 달려있으므로 각 컴포넌트를 따로 평가하는 것으로는 부족하다.
또한, 버전 관리 (versioning)도 훨씬 복잡해진다. 체인 전체를 하나의 아티팩트(artifact)로 버전 관리하고, 그 변경 이력을 추적하며, 각 컴포넌트의 입출력을 모두 기록해야 한다.
여기서는 Vertex AI가 이 체이닝과 증강 단계에 매우 적합한 플랫폼이라고 강조(+홍보)하는데, Grounding as a Service, Extensions, 벡터 검색(Vector Search), Agent Builder 등 체인을 구축·관리할 수 있는 다양한 도구들이 있다고 한다.
LangChain과도 통합되어 있어서, 이런 종류의 애플리케이션을 개발할 때 인기 있는 오픈소스 프레임워크를 함께 활용할 수 있다.
하지만 가끔은 아무리 프롬프트를 다듬고 체인을 구축해도 충분하지 않을 때가 있는데, 이럴 때는 모델 자체를 조정해야 한다.
바로 여기가 튜닝과 학습 (Tuning and Training) 단계로 넘어가는 부분!
🔧 프롬프트만으로 부족할 때: 튜닝과 학습
앞에서 말했던 것처럼, 프롬프트만으로 할 수 있는 것은 한계가 있다. 모델 내부를 손봐야 할 때가 있는데, 그럼 구체적으로 어떤 작업을 하게 될까?
파운데이션 모델을 튜닝한다는 것은, 특정 작업이나 도메인에서 더 잘 작동하도록 모델을 맞춤화하는 것이다.
여기에는 몇 가지 일반적인 접근 방식이 있다.
- 지도학습 파인튜닝 (Supervised Fine-Tuning)
- 라벨이 붙은 데이터셋을 가지고 모델을 학습시키는 방식이다.
- 즉, 주어진 입력에 대해 올바른 출력을 예측하도록 모델을 가르치는 것이다.
- 인간 피드백 기반 강화학습 (RLHF, Reinforcement Learning from Human Feedback)
- 인간의 피드백을 이용해 보상 모델 (reward model)을 훈련시키고, 그 보상 모델로 LLM이 튜닝 과정에서 어떤 출력을 낼지 안내한다.
- 댕댕이를 간식으로 훈련시키는 것처럼, 좋은 행동에는 보상을 주어 학습시키는 방식이다.
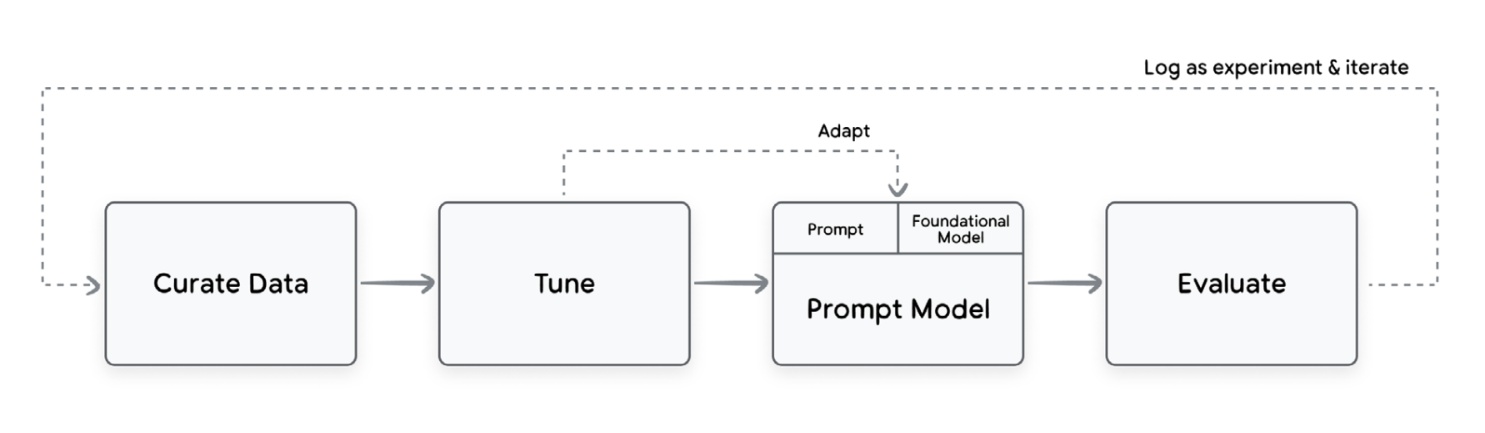 Putting together chains, prompted models and model tuning
Putting together chains, prompted models and model tuning
MLOps 관점에서는, 튜닝 과정에서 생성되는 모든 아티팩트를 추적할 수 있어야 한다.
- 데이터
- 사용한 파라미터
- 성능지표
모두 관리가 필요하다.
여기서 또다시 vertex AI 광고를 시작하는데, 그냥 적어보자면:
Vertex AI에는 Model Registry나 Vertex Pipelines 같은 도구들이 있다고 한다.
또한, Dataplex에서 예측 AI와 생성형 AI의 데이터/모델을 한 곳에서 관리하는 통합 거버넌스 (unified governance) 기능도 제공한다고 함
즉, 서로 다른 AI 워크로드를 별도의 시스템에서 관리할 필요 없이 모두 한 플랫폼에서 다룰 수 있으니 훨 간편해진다는 것!
팟캐스트에서는 추가로 지속적인 학습 (Continuous Training)과 지속적인 튜닝 (Continuous Tuning)에 대해서도 이야기한다.
하지만 대규모 모델의 경우에는, 매번 모델을 처음부터 다시 학습하는 것은 비용이 너무 크니 주로 더 실용적인 지속적인 튜닝을 선택한다.
💸 현실적인 고민: 비용과 효율성
여기까지 개발 및 실험 (Develop & Experiment) 단계와 모델 튜닝 및 학습 (Tuning & Training) 단계에서 모델을 어떻게 선택하고, 실험하고, 조정할지에 대해 살펴보았다.
여기서 중요한 현실적 고민 중 하나가 바로 비용인데, 이건 너무나도 당연한 이야기이다.
이런 대규모 모델을 다루는 것은 정말 많은 비용이 들어간다.
특히 GPU나 TPU 같은 특수 하드워어를 사용할 경우 비용이 훨씬 커진다.
팟캐스트에서는 이런 비용을 관리하기 위한 방법 중 하나로 모델 양자화 (model quantization) 같은 기술을 소개했다.
양자화는 모델을 더 가볍게 만들어서, 필요한 계산량과 저장 공간을 줄여 비용을 절감하는 방식이다.
하지만 모델만 잘 고르고 효율화를 한다고 해서 운영이 끝나는 게 아니다.
생성형 AI 시스템을 ‘현실에서 안정적으로 굴러가게’하려면 그 모델을 움직이게 하는 데이터 관리 (data practices)가 필수적이다.
그래서 다음으로는 이 대규모 모델을 뒷받침하는 데이터의 관리와 운영에 대한 이야기로 이어진다.
📊 개발된 시스템을 뒷받침하는: 데이터 관리
전통적인 머신러닝에서는 데이터가 사실상 모든 것이었고, 데이터가 모델의 동작 방식을 결정했다.
그리고 생성형 AI에서도 초기 사전학습 (pre-training)에 사용되는 데이터는 여전히 중요하다.
So, in traditional ML, the data was basically everything. It dictated how the model behaved.
하지만 이제는 모델을 다양한 데이터로 어떻게 적응시키는지가 그만큼 중요해졌다.
생성형 AI에서는 아주 적은 데이터만으로도 프로토타입을 만들 수 있는 경우가 많다.
몇 개의 예제나 프롬프트 템플릿만으로도 흥미로운 결과를 만들어낼 수 있지만, 그렇다고 데이터 관리가 간단해지는 건 아니다!
어떠한 과제들이 있을까?
먼저, 훨씬 더 다양한 데이터 유형을 다뤄야 한다.
전통적인 머신러닝에서는 주로 입력 변수 (input features)와 타겟 변수 (target variable) 정도를 관리하면 되었다.
하지만 생성형 AI에서는 상황이 완전히 달라진다.
예를 들면, 아래와 같은 데이터들이 모두 필요하다:
- 조건부 프롬프트 (conditioning prompts)
- few-shot 예제
- 외부 API에서 가져온 grounding 데이터
- RLHF에 사용되는 인간 피드백 데이터
이런 다양한 데이터가 시스템에 함께 들어오게 된다.
그래서 이제 단순히 ETL 파이프라인만 구축하는 문제가 아니라 전체 데이터 생태계를 관리해야 한다.
So, it’s not just about building ETL pipelines anymore. It’s about managing this whole ecosystem of data.
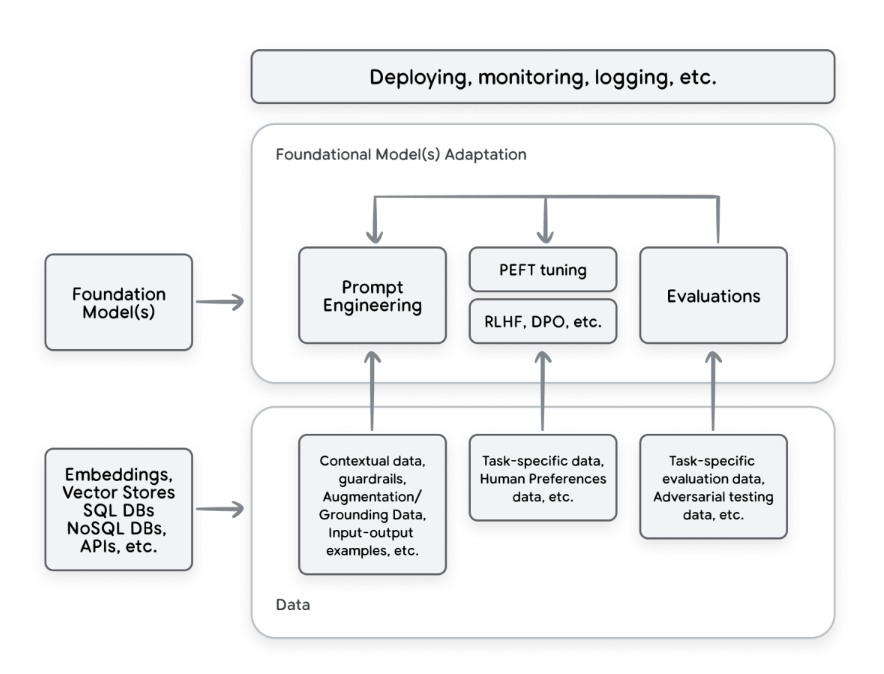 example of high-level data and adaptations landscape for developing gen AI applications using existing foundation models
example of high-level data and adaptations landscape for developing gen AI applications using existing foundation models
이때 기존의 MLOps와 DevOps의 관행이 큰 도움이 되지만, 여기에 생성형 AI 특유의 새로운 요소들이 더해져야 한다.
이렇게 서로 다른 데이터 유형들을
- 버전 관리할 수 있고(versionable),
- 추적할 수 있고 (trackable),
- 재현 가능한 (reproducible) 방식으로
관리·발전·적응·통합할 수 있는 시스템이 필요하다.
또한, 팟캐스트에서는 대규모 모델을 데이터 엔지니어링 작업에도 활용하는 방법을 간단히 소개한다.
여기서 예시로 든 것은 합성 데이터 (synthetic data) 생성인데, 이런 작업이 요즘 큰 화제라고 한다.
이 모델을 사용하면 실제 데이터와 아주 비슷한 인공 데이터를 만들어 낼 수 있으며,
기존 데이터셋의 빈틈을 메우거나, 더 다양한 학습 시나리오를 구축하는 데 유용하게 활용할 수 있다.
🎯 핵심 관문: 생성형 AI의 평가
이제 생성형 AI의 평가 (evaluation) 단계로 넘어가면, 중요한 과제가 하나 생긴다. 바로 우리는 파운데이션 모델의 학습 데이터 분포를 정확히 알지 못한다는 점이다.
우리의 특정한 유스케이스를 충실히 반영하고, 중요한 모든 시나리오를 포괄할 수 있는 맞춤형 평가 데이터셋 (custom evaluation datasets)을 직접 만들어야 하며, 이 평가 데이터를 생성하고 선별하는 과정에 언어 모델을 활용할 수도 있다.
그래서 평가 (evaluation)는 여기서 다루는 다음 주요 주제이다.
프롬프트 엔지니어링만 하더라도, 그 결과가 효과적인지 아닌지를 알아야 하기 때문에 평가가 필요하다.
평가는 생성형 AI 시스템 개발 전체 과정에서 핵심 요소이다.
Evaluation is core to the whole development process.
초기에는 사람이 직접 평가를 하지만, 프로젝트가 안정화되거나 발전하면서 점점 자동화된 평가 방식으로 전환하게 된다.
속도(speed)와 신뢰성(reliability)을 위해서는 평가 자동화가 매우 중요하지만, 생성형 AI의 경우 평가를 자동화하는 게 쉬운 일이 아니다.
-
출력의 복잡성 및 고차원성
생성된 결과물이 종종 복잡하고 고차원적(high-dimensional)이기 때문이다.
예를 들어, 생성된 이미지나 텍스트의 품질을 어떻게 수치화할 수 있을까?BLEU, ROUGE 같은 기존의 평가 지표들도 있긴 하지만, 이런 지표만으로는 생성 결과의 전체적인 품질을 설명하기에 부족한 경우가 많다.
그래서 맞춤형 평가 방법 (custom evaluation methods)이 굉장히 중요해진다.그럼 ‘맞춤형 평가 지표’ (custom metrics)란 어떤 것일까?, 생성형 AI 시스템에서 ‘좋은 결과’를 정의한다는 게 어떤 의미일까? 라는 질문이 생기는데, 이건 전적으로 유스케이스에 따라 달라진다.
일부 작업에서는 명확한 정답(label)이 있을 수 있지만, 어떤 작업은 더 주관적이다.
그래서 애플리케이션에 중요한 기준들을 정의하고, 그 기준들을 기반으로 평가를 해야한다.기준의 몇 가지 예시:
- 사실의 정확성 (factual accuracy)
- 일관성 (coherence)
- 창의성 (creativity)
- 스타일 (style)
이런 요소들을 정의하고, 그에 따른 평가를 진행하는 방식이다.
그리고 최근에는 흥미로운 평가 방식들이 등장하고 있다.
다른 대형 언어 모델을 심판(judge) 역할로 활용하는 방식인데, 프롬프트를 통해 생성된 텍스트의 품질을 여러 기준에 따라 평가하도록 모델에게 요청하는 것이다.여기서는 AI가 AI를 평가하는 AutoSxS (Automatic Side-by-Side)라는 평가 기법도 언급하는데, 이 방식은 꽤 잘 작동한다고 한다.
하지만 이 모든 것들은 생성형 AI 평가가 본질적으로 주관적인 요소를 포함하고 있다는 점을 보여준다.
💬 어떤 사람이 '좋은 결과물'이라고 생각하는 것이 다른 사람에게는 아닐 수도 있다.그래서 자동화된 평가가 실제 인간의 판단과 잘 일치하도록 만드는 것이 매우 중요하다.
그렇지 않으면, 실사용자들이 중요하게 생각하지 않는 지표를 최적화하는 무의미한 시스템이 만들어질 수도 있다. -
정답 데이터의 부재 (lack of ground truth data)
이 또한 평가를 위한 중요한 과제이다.
이를 해결하기 위한 방법 중 하나로 합성 데이터 (synthetic data)를 생성해 사용하는 것도 있는데, 완벽하진 않지만 일시적인 보완책으로는 꽤 유용할 수 있다. -
적대적 공격에 대한 취약성
마지막으로, 적대적 공격 (adversarial attacks)에 대한 테스트의 중요성도 강조한다.
모델이 악의적으로 유도되어 해롭거나 부적절한 출력을 생성하도록 유도당하는 경우에 대비하는 것이며,
생성형 AI에 대한 보안 테스트 (security testing) 라고 볼 수도 있다.It’s kind of like security testing for generative AI.
따라서 이런 공격에도 견딜 수 있는 견고한 시스템을 만드는 것이 중요하다.
*아래 표 참고 (생성형 AI 평가를 위한 유용한 접근 방식들)
 Key suggestion to approach evaluation of gen AI systems
Key suggestion to approach evaluation of gen AI systems
💭 오늘 챙겨간 것들
- 생성형 AI의 운영 생애주기는 탐색 → 실험 → 평가 → 배포 → 거버넌스
- 이번 글은 평가 단계 중심으로 → 프롬프트 체이닝, 튜닝 방식, 평가 지표/데이터셋을 살펴봤다.
- 체이닝은 문제 해결 흐름을 설계하는 작업 → LLM의 출력을 더 안정적이고 일관되게 만든다
- 튜닝은 목적에 따라 LoRA, RAG 등 선택 → 성능 vs 비용 vs 유지보수 고려
- 평가는 단순 정확도뿐 아니라 정확성, 편향성, 유사성, 유용성 등 다양한 기준이 필요하다.
이제 모델은 잘 만들었고, 평가까지 마쳤다면, 배포를 할 차례이다!
다음 글에서는 생성형 AI 시스템의 배포와 거버넌스, 그리고 운영 환경에서의 지속적 모니터링과 신뢰 가능한 시스템 운영을 위한 핵심 개념들을 다뤄본다.