[Kaggle Gen AI] Day 5 - 생성형 AI 운영을 위한 시작점: 탐색과 모델 선택의 전략 🚀
![[Kaggle Gen AI] Day 5 - 생성형 AI 운영을 위한 시작점: 탐색과 모델 선택의 전략 🚀](/assets/images/20250402/day5_1.png)
지난 글까지가 Day 4였고, 이 게시물부터 마지막 Day 5의 시작이다.
Day 5에서는 생성형 AI의 모든 잠재력을 현실에서 제대로 작동하도록 어떻게 바꿀 수 있을까라는 문제를 다뤄보려고 한다!
간단하게 말하면 생성형 AI의 MLOps 전 과정을 다루는 생성형 AI를 ‘운영화’하는 개념이라고 할 수 있다.
생성형 AI가 큰 주목을 받으며 다양한 활용 사례가 나오고 있지만, 그걸 기반으로 어떻게 신뢰성과 안정성을 갖춘 시스템을 만들 수 있을까?
여기서 MLOps가 중요한 역할을 한다고 한다.
이 프로그램은 Kaggle이 구글과 함께 진행하는 거라서, 이를 위한 플랫폼으로 Vertex AI에 초점을 맞추고 있다.
추가로, 에이전트 운영 (AgentOps)에 대해서도 다뤄볼 예정.
⚙ DevOps와 MLOps 개념
본격적인 이야기로 들어가기 전에, DevOps의 개념부터 짚고 넘어가자면, DevOps는 소프트웨어 개발을 더 원활하고 빠르게 만들기 위해, 개발팀과 운영팀이 협업하고 자동화를 도입하는 접근 방식이다.
MLOps는 이런 DevOps의 원칙, ‘협업과 자동화’ (collaboration, automation) 를 머신러닝에 적용하는 것이다.
머신러닝에서는 전통적인 소프트웨어 개발에서 생기지 않는 과제들이 있는데:
- 데이터가 유효한지 검증해야 하고, (make sure data is valid)
- 모델을 평가해야 하며, (evaluate models)
- 드리프트같은 문제를 감지하기 위해 지속적으로 모니터링을 해야 한다. (monitor them for things like drift)
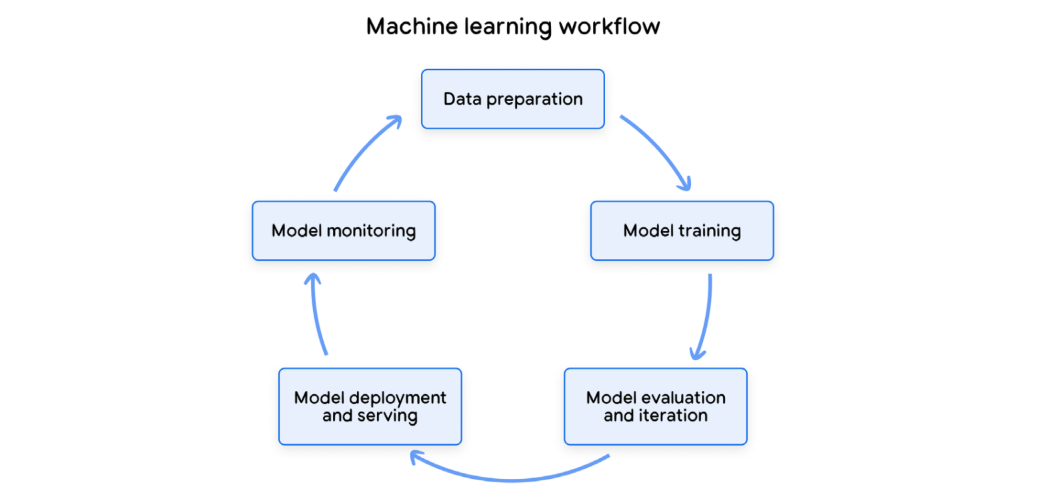 Machine learning workflow
Machine learning workflow
특히 파라미터가 엄청나게 많은 복잡한 모델을 다룰 때는 재현성 (reproducibility)이 굉장히 중요해진다.
🔄 생성형 AI 생애주기와 파운데이션 모델
여기에 생성형 AI가 더해지면, 상황은 더 복잡해진다.
그래서 팟캐스트에서는 생성형 AI 시스템의 전체 생애주기 (lifecycle)를 단계별로 정리하고 있으며, 크게 다섯 가지의 핵심 단계가 있다.
- 탐색 (discover)
- 개발 및 실험 (develop and experiment)
- 평가 (evaluate)
- 배포 (deploy)
- 거버넌스 (govern)
생성형 AI에서는 지속적인 개선 (continuous improvement)을 하는 방식이 약간 다른데,
항상 모델을 처음부터 새로 학습시키는 것이 아니라, 대부분의 경우에는 이미 강력한 파운데이션 모델 (Foundation Model)을 시작으로 삼고, 이를 조정하고 적응시키게 된다.
그래서 이 과정은 지속적으로 모델을 미세 조정 (tweaking and refining)하고, 새로운 버전을 시도 (trying out newer versions of the foundation models)해보고, 다른 모델을 조합 (combining different models)해 보면서, 성능, 비용, 속도 등 각자의 요구에 맞는 균형점을 찾아가는 일에 더 가깝다.
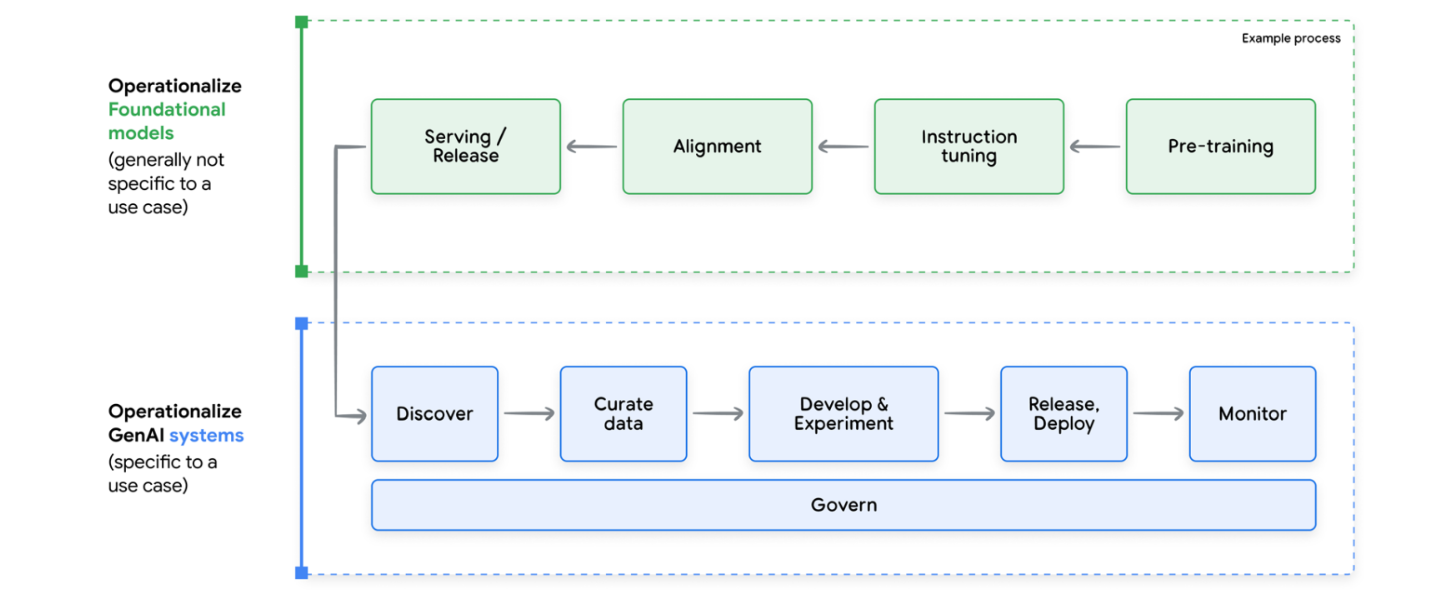 Lifecycle of a Foundation Model & gen AI system and relative operationalization practices
Lifecycle of a Foundation Model & gen AI system and relative operationalization practices
여기서 다룰 내용의 핵심은 바로 파운데이션 모델 위에 구축된 생성형 AI 애플리케이션을 운영화하는 방법이다.
이 초대형 모델들이 처음에 훈련되는 방식에 대해서는 깊게 들어가지 않고 (완전히 다른 이야기이기 때문), 이미 존재하는 모델을 도구 삼아서 실제로 활용할 수 있게 만드는 것에 초점을 맞출 것이다.
🔍탐색 단계: 적합한 모델 찾기
첫 번째 단계는 ‘탐색’ (discover)이다.
예전에는 선택할 수 있는 머신러닝 모델이 손에 꼽을 정도로 몇 가지밖에 안 되었지만, 지금은 오픈 소스 모델, 상용 모델 등 정말 다양한 모델들이 끊임없이 등장하고 있다.
그래서 여기서는 모든 상황에 만능으로 통하는 단일 솔루션은 없다는 점을 강조한다.
어떤 모델이 적합한지는 각자의 사용 사례, 데이터, 제약 조건에 달려있다.
It depends on your use case, your data, your constraints. There’s no silver bullet.
그래서 이 탐색 (discover) 단계는 결국 목적에 가장 적합한 도구를 찾아내는 과정이라고 할 수 있다. 이때 고려해야 할 핵심 요소가 몇 가지 있는데:
- 품질 (quality)
- 먼저 이 모델이 실제로 우리가 원하는 작업을 얼마나 잘 수행할 수 있는지 평가해야 한다.
- 벤치마크 점수를 살펴볼 수 있고, 직접 소규모 테스트를 진행해보면서 몇 가지 프롬프트를 입력해 어떤 결과가 나오는지 확인할 수도 있다.
- 지연 (latency)
- 실시간 응답이 필요한 챗봇같은 서비스를 만든다면, 이 지연이 큰 문제가 될 수 있다.
- 비용 (cost)
- 인프라 비용, HW와 SW 비용, 사용 (usage) 비용 등등 모두를 고려해야 한다.
- 비용은 어떤 모델을 어떻게 활용하느냐에 따라 크게 달라질 수 있기 때문!
- 법적·규제적 준수 (legal and compliance)
- 초기에 충분히 검토를 하지 않으면 나중에 큰 문제가 될 수 있는 부분 중 하나이다.
추가로, 여기서는 이런 모델 과부하 문제 (model overload)를 해결할 방법으로 Vertex Model Garden을 소개하고 있다.
홍보같긴 하지만 그냥 같이 정리해보자면, Model Garden은 구글 자체 모델, 파트너 모델, 오픈소스 모델들을 한 곳에 모아둔 큐레이션 된 컬렉션이라고 한다.
각 모델에는 모델 카드 (model card)가 함께 제공되어서 성능, 권장 사용 사례, 한계 등 모든 주요 정보를 한 눈에 볼 수 있다.
그래서 필요에 맞는 모델을 찾기 위한 원스톱 쇼핑 공간이라고 함!
So, it’s like a one-stop shop for finding the right model for your needs.
🧪 개발 및 실험 단계
이제 자신의 목적에 맞는 모델을 하나 또는 몇 가지 찾았다 치고! 다음 단계로 넘어간다
이제부터는 개발 및 실험 (Develop & Experiment) 단계로 들어가는데, 이 단계는 전통적인 머신러닝 개발과 마찬가지로 반복 (iteration)이 핵심이다.
- 데이터를 다듬고, (refining data)
- 모델을 가지고 실험해 보고, (playing around with the model)
- 결과를 평가한 뒤, (evaluating the results)
- 다시 돌아가서 수정하는 과정을 반복하는 것이다. (go back and tweak things)
여기까지가 바로 고전적인 실험 사이클이고,
팟캐스트에서는 파운데이션 모델 패러다임 (Foundation Model Paradigm)에 대해 이야기한다.
이러한 파운데이션 모델은 우리가 사용해왔던 기존의 예측 모델과 어떻게 다를까?
먼저, 다목적 (multi-purpose) 모델이라는 점이다
- 얘네들은 하나의 특정 작업만을 위해 학습된 것이 아니며
- 매우매우 방대하고 다양한 데이터셋으로 학습되어
- 여러 가지 다양한 작업에 적용할 수 있는 능력을 가지고 있다.
또한, 이 모델들은 창발적 속성 (emergent properties)을 보인다.
- 그러니까, 명시적으로 학습하지 않은 일까지도 수행할 수 있다는 것이다.
-
아이에게 알파벳을 가르쳤더니 어느 순간 시를 쓰기 시작하는 것과 비슷하다고 할 수 있다.
It’s kind of like you teach a kid the alphabet and then suddenly they start writing poetry.
그리고 이 파운데이션 모델에서는 입력 (input)이 전부이다. 이 모델들을 입력 프롬프트에 아주 민감하게 반응해서, 작은 변화만으로 출력 결과가 크게 달라질 수 있다.
이건 전통적인 머신러닝에서는 크게 신경 쓰지 않아도 되는 부분이다. (어느 정도의 피처 엔지니어링(feature engineering)은 필요하지만 입력 자체는 대체로 명확히 정의되어 있는 편이니까)
🔊 Prompted Model Component
팟캐스트에서는 prompted model component라는 개념을 소개하면서 이 부분을 조금 더 깊이 설명하는데,
전통적인 AI에서는 모델과 입력이 있으면 충분했지만, 생성형 AI에서는 추가적인 층인 프롬프트가 있다. 그리고 단일 프롬프트만 사용하는 것이 아니라, 보통 프롬프트 템플릿 (prompt template)을 사용한다.
프롬프트 템플릿은 모델에 지시사항과 예제를 체계적으로 제공하는 방식이다. 템플릿 안에 사용자의 입력을 넣을 수 있는 placeholder가 있을 수 있다.
아래 그림에서 보이는 것처럼, 프롬프트 템플릿과 사용자 입력이 합쳐져 완전한 프롬프트를 구성하게 되며, 이걸 모델에 입력한다.
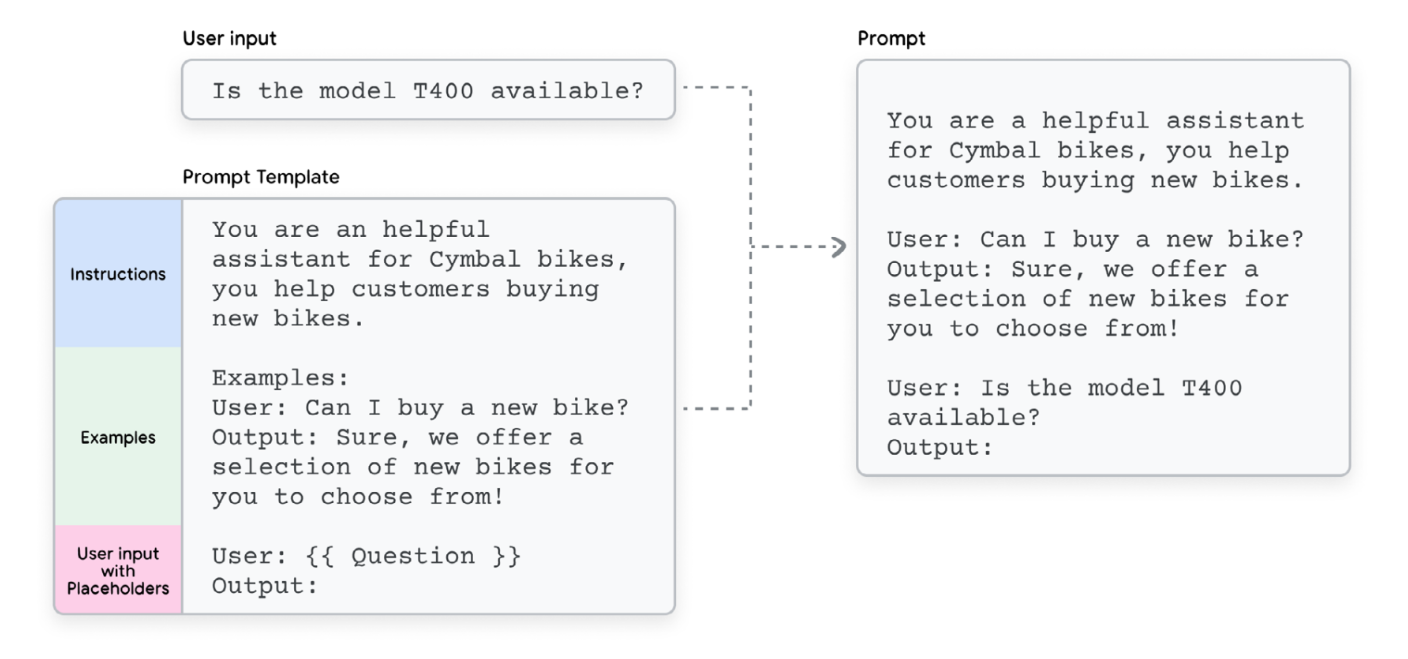 How Prompt Template and User input can be combined to create a prompt
How Prompt Template and User input can be combined to create a prompt
Prompted Model Component란 이렇게 모델과 프롬프트가 결합된 것으로, 생성형 AI 애플리케이션에서 실제로 무언가를 수행할 수 있는 최소 단위라고 할 수 있다.
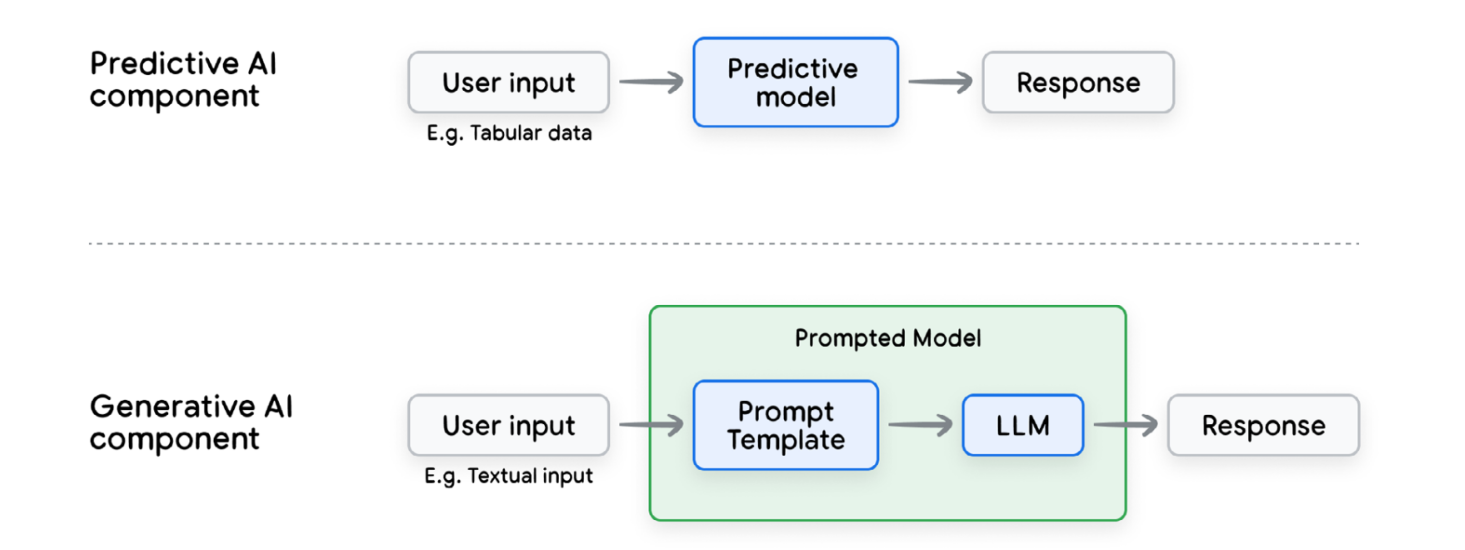 Predictive AI unit compared with the gen AI unit
Predictive AI unit compared with the gen AI unit
요게 특별한 이유는, 실험 방식 자체가 달라지기 때문이다.
전통적인 머신러닝에서는 모델의 파라미터를 조정하고, 그 결과를 평가하는 방식이었는데, 생성형 AI에서는 프롬프트 자체를 조정하기도 한다.
그래서 프롬프트 엔지니어링이 완전히 새로운 기술 분야가 되는 것!
But with generative AI, we’re also tweaking the prompt itself, which means prompt engineering becomes this whole new skill set.
프롬프트 엔지니어링은 단순히 질문이나 명령문을 입력하는 것이 아니라, 모델이 어떻게 작동하는지, 언어를 어떻게 해석하는지, 어떤 프롬프트에 반응하는지를 깊이 이해해야 한다.
이 작업은 많은 시행착오를 필요로 하며
- 어떤 방식을 시도해보고
- 출력을 평가하고,
- 프롬프트를 다시 조정하고
- 다시 시도하는 과정을 거친다.
It’s a lot of trial and error. You try one thing, you evaluate the output, you tweak the prompt, you try again.
프롬프트와 평가가 반복되는 순환 과정을 아래 그림에서 확인할 수 있다.
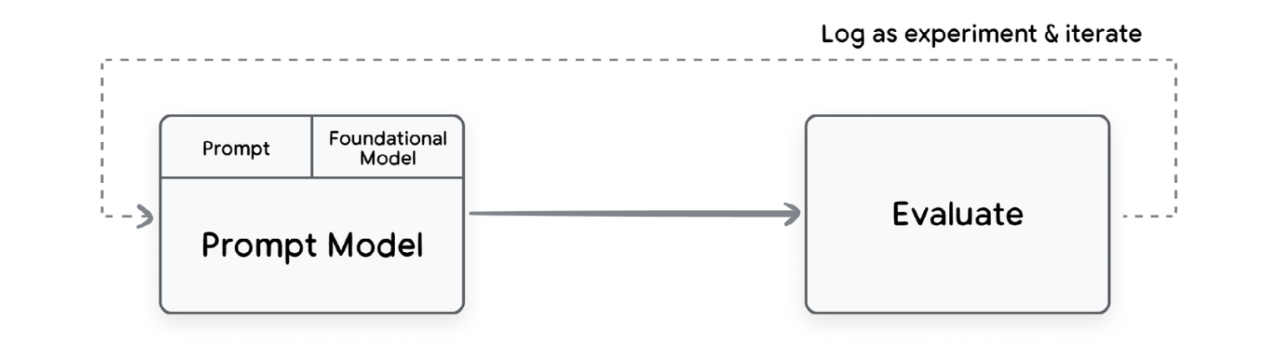 The activity of prompt engineering
The activity of prompt engineering
🎲 프롬프트의 데이터성과 코드성
그리고 여기서 또 흥미로운 개념을 하나 소개하는데 바로:
“프롬프트는 데이터이고, 프롬프트는 코드다” (prompt is data and prompt is code)라는 아이디어이다.
첨엔 뭔 소리인가 싶었는데, 여기서 설명하기로는:
프롬프트의 일부는 본질적으로 데이터이다.
예를 들어서 few-shot이나, 참고하는 지식 베이스, 사용자가 처음 입력한 질의(query)는 모두 데이터에 해당한다.
이런 부분에서는 데이터 중심의 MLOps 관행이 필요하다는 것이다.
- 데이터 검증 (data validation)
- 드리프트 탐지 (drift detection)
- 데이터 수명 주기 관리 (data life cycle management)
- 등등
그런데 프롬프트의 다른 부분은 코드에 더 가깝다.
- 지침 (instructions)
- 템플릿 자체 (template itself)
- 모델이 엉뚱하게 작동하지 않도록 만드는 가이드라인
이것들은 코드의 성격을 띈다.
그래서 이런 부분에는 코드 중심의 관리가 필요하다는 것이다.
- 버전 관리 (version control)
- 테스트 (testing)
- 승인 프로세스 (approval processes)
- 등등
이렇게 프롬프트 안에 데이터와 코드의 이중성이 존재한다는 개념이 ‘prompt is data and prompt is code’이며, 이 아이디어에 따라 우리는 데이터와 코드 모두를 함께 관리해야 한다고 한다.
또한, 재현성을 확보하기 위해 어떤 프롬프트 버전이 어떤 모델 버전과 가장 잘 맞는지 추적할 수 있어야 한다.
That’s essential for reproducibility.
💭 오늘 챙겨간 것들
✔️ 생성형 AI의 운영을 위해선 DevOps처럼 협업과 자동화가 핵심이고, 이를 ML에 적용한 개념이 MLOps다.
✔️ 생애주기는 탐색 → 실험 → 평가 → 배포 → 거버넌스로 이어지며,
✔️ 이 중 탐색 단계에서는 ‘무조건 좋은 모델’이 아니라 ‘내 목적에 맞는 모델’을 고르는 것이 중요했으며
✔️ 실험 단계에서는 파운데이션 모델을 기반으로 반복적인 조정과 개선을 진행한다.
✔️ 마지막으로, 프롬프트는 데이터이자 코드이기 때문에 → 데이터 관리 + 코드 관리를 함께 고려해야 한다는 것!
다음 글에서는 생성형 AI의 운영에서 체이닝, 튜닝, 데이터를 중심으로 한 평가 단계를 알아볼 예정이다.