[Kaggle Gen AI] Day 1 - Decoder-Only 구조, 왜 LLM은 디코더만 쓸까? 🚀
![[Kaggle Gen AI] Day 1 - Decoder-Only 구조, 왜 LLM은 디코더만 쓸까? 🚀](/assets/images/20250402/day1_1.png)
지난 게시물에서는 LLM의 기반이 되는 Transformer 구조, 특히 그 안에서 작동하는 Self-Attention과 Multi-Head Attention 메커니즘을 중심으로 살펴봤다.
이번 게시물에서는, 요즘의 GPT 시리즈처럼 Decoder만 사용하는 구조(Decoder-Only Architecture)가 왜 LLM에서 주류가 되었는지, 그 장점은 무엇인지 정리해보겠다.
Transformer 구조의 응용이자 진화 형태인 이 구조를 이해하면, 최신 LLM들이 어떤 방식으로 학습되고 동작하는지 감을 잡을 수 있을 것이다!
🔧 Decoder-Only 구조란?
초기 Transformer는 Encoder-Decoder 구조로 제안되었지만, 최근 대부분의 LLM(GPT 계열 etc.)은 Decoder-Only 구조를 사용하고 있다.
왜 Encoder 없이 Decoder만 쓰는 걸까?
-
텍스트 생성에만 집중할 때는 Encoder가 필요 없기 때문!
➡ 글쓰기나 대화처럼 입력을 해석하기보다는, 다음 단어를 예측하는 일이 더 중요한 경우에는, 복잡한 Encoder는 오히려 불필요할 수 있다. -
원래 Encoder는 입력 전체를 보고 문맥을 요약한 벡터 표현을 만들어주는 역할을 한다. (create this representation of the whole input sequence up front)
하지만 Decoder-Only 모델은 그 과정을 생략하고 이전까지 입력된 토큰만을 바탕으로 다음 토큰을 하나씩 예측하는 방식으로 작동한다.
Decoder-Only만의 핵심 기술: “Masked Self-Attention”
-
Decoder-Only 모델은 특수한 Self-Attention, 즉 Masked Self-Attention이라는 방식을 사용한다.
-
이 방식은 모델이 현재 시점 이전의 토큰만 볼 수 있도록 제한함으로써 사람이 말을 하거나 글을 쓸 때처럼, 순차적으로 자연스럽게 예측하도록 만든다.
-
쉽게 말하면, Masked Self-Attention으로 미래를 차단한다는 것!
🧠 더 크고 더 똑똑하게: Mixture of Experts (MoE)
Decoder-Only 구조는 텍스트 생성에 특화된 단순하고 효율적인 구조지만, 성능을 높이기 위해서는 모델의 크기(파라미터 수)를 키워야 한다는 한계도 존재한다.
MoE의 구조는?
-
하나의 거대한 모델 안에, 역할이 다른 여러 개의 전문가 모델(experts)이 들어있따.
-
하지만 매 입력마다 모든 전문가를 다 쓰는 게 아니라, 게이팅 네트워크(Gating Network)가 판단해서 그 중 일부 전문가만을 선택적으로 활성화한다.
- 예를 들어, 수십억 개의 파라미터를 가진 모델이라도, 하나의 입력을 처리할 때 활성화되는 파라미터는 일부 전문가에게 해당하는 부분만 사용된다.
➡ 즉, 전체 파라미터를 모두 계산하지 않아도 되기 때문에, 모델은 더 크면서도 더 빠르게 작동할 수 있다.
⚡ Q&A
Q1. GPT 같은 Decoder-Only 모델은 Encoder 없이도 Pretraining이 가능한가?
✅ GPT는 Encoder 블록 없이도 사전학습이 가능하다.
다만, 여기서 말하는 “Encoder가 없다”는 말은 Transformer 구조 내에서 Encoder 블록이 없다는 의미. 입력 자체를 처리하기 위한 Embedding 레이어는 반드시 포함되어 있다!
➡ GPT Pretraining 구조 한눈에 보기
- 구조
- GPT는 Decoder 블록만 여러 개 쌓은 구조로 구성되어 있음
- 하지만 입력을 토큰화하고 벡터로 바꾸는 Embedding 과정은 존재함 (이건 Encoder가 아니라, 입력 처리층)
- 학습 방식
- 텍스트를 한 줄로 연결하고, 왼쪽 → 오른쪽으로 순차적으로 다음 토큰을 예측
1 2
Input: "The cat sat on the" Target: "mat"
- 이때 Masked Self-Attention을 사용하여
→ 현재 시점 이후의 단어는 보지 못하도록 막음
→ 마치 사람이 글을 쓰듯 자연스럽게 학습됨
- 텍스트를 한 줄로 연결하고, 왼쪽 → 오른쪽으로 순차적으로 다음 토큰을 예측
- BERT와 비교하면?
- BERT는 문장 전체를 인코딩하고, 일부 [MASK]된 단어를 예측하는 방식
→ 그래서 Encoder 블록이 필요 - GPT는 순차적으로 생성만 하기 때문에, Encoder 없이도 학습 가능
💬 정리: GPT는 Encoder 블록 없이도 학습 가능하지만, Embedding 레이어는 포함되어 있으며, 이건 "인코딩"과 다르다! - BERT는 문장 전체를 인코딩하고, 일부 [MASK]된 단어를 예측하는 방식
Q2. Transformer가 Encoder-Decoder 구조인지, Decoder-Only 구조인지는 어떻게 결정되고, 내부 구성은 서로 어떻게 다른가?
✅ Transformer 모델의 구조는 “전체 레이어를 어떻게 쌓았느냐”에 따라 결정된다.
Encoder-Decoder인지, Decoder-Only인지 여부는 각 레이어 내부 구성보다 전체 구조의 설계 방식에 달려 있다. 하지만 내부 구성(특히 Attention 부분)은 매우 유사하고, Embedding 레이어는 두 구조 모두에 공통적으로 존재함!
- Embedding은 모든 구조에 필요하다!
- 입력을 벡터로 바꾸는 Embedding Layer는
- Encoder-Decoder 모델
- Decoder-Only 모델 모두에 공통으로 포함된다.
- 다만 Embedding의 공유 여부나 위치는 모델에 따라 조금씩 다를 수 있다. (e.g. T5는 input/output embedding을 공유)
- 입력을 벡터로 바꾸는 Embedding Layer는
- Layer 내부 구성은 거의 비슷함!
- 기본적인 Transformer Layer는 다음과 같은 구성:
LayerNorm → Multi-Head Attention → +ResidualLayerNorm → Feed Forward → +Residual
- 다만 구조별 차이점은 Attention의 종류에서 발생한다:
구조 사용되는 Attention Encoder Layer Self-Attention (전체 시퀀스 참조 가능) Decoder Layer Masked Self-Attention + Cross-Attention Decoder-Only Layer Masked Self-Attention만 사용 📌 Cross-Attention은 Encoder의 출력을 Decoder가 참조할 때만 필요하므로, Decoder-Only 구조에는 등장하지 않는다.
- 기본적인 Transformer Layer는 다음과 같은 구성:
📊 Encoder Layer vs Decoder Layer 내부 구조 비교표
| 항목 | Encoder Layer | Decoder Layer |
|---|---|---|
| 입력 | 입력 문장의 토큰 시퀀스 (자기 자신만 참조) |
Decoder 이전 출력 토큰 (자기 자신 + Encoder 출력 참조) |
| Self-Attention 종류 | ✅ Full Self-Attention (모든 토큰 간 자유롭게 attention 가능) |
✅ Masked Self-Attention (자기 앞 토큰까지만 참조) |
| Cross-Attention | ❌ 없음 | ✅ 있음 (Encoder의 출력 벡터에 attention 수행) |
| Attention 블록 수 | 1개 (Self-Attention) | 2개 (Masked Self-Attention + Cross-Attention) |
| Layer 구성 |
① LayerNorm ② Multi-Head Self-Attention ➕ Residual ③ LayerNorm ④ Feed Forward ➕ Residual |
① LayerNorm ② Masked Multi-Head Self-Attention ➕ Residual ③ LayerNorm ④ Cross-Attention ➕ Residual ⑤ LayerNorm ⑥ Feed Forward ➕ Residual |
| 적용 목적 | 입력 전체를 이해하고 요약 (representation 생성) |
입력을 기반으로 출력 시퀀스를 생성 (sequence generation) |
| 대표 모델 | BERT, T5 (Encoder 부분), 원래 Transformer의 Encoder |
GPT, T5 (Decoder 부분), BART Decoder 등 |
👀 구조 비교: Encoder-Decoder vs Decoder-Only 아키텍처
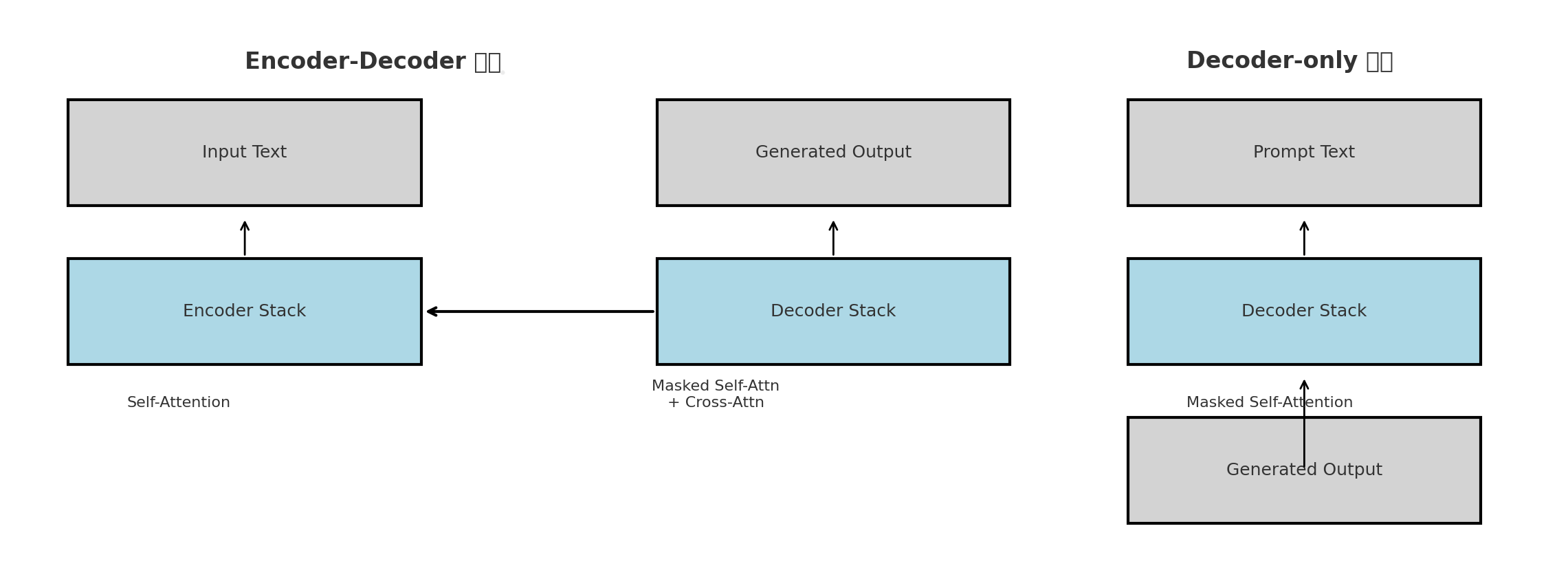 📌 Transformer 구조 비교: Encoder-Decoder와 Decoder-Only 한 눈에 정리!
📌 Transformer 구조 비교: Encoder-Decoder와 Decoder-Only 한 눈에 정리!
💭오늘 챙겨간 것들
지금까지 정리한 내용을 작성해보자면:
- What Transformers are
- Self-attention
- Multi-head attention
- Layer normalization
- Residual connections
- Feed forward networks
- Encoder-Decoder vs Decoder-only
- Masked attention
- MoE (Mixture of Experts)
이제 “LLM은 왜 지금의 모습이 되었는가?”라는 흐름을 따라가 볼 차례!
다음 글에서는 LLM의 발전 과정(How LLMs evolved over time)을 중심으로, GPT 시리즈와 같은 모델들이 어떻게 확장되고 진화해 왔는지 함께 살펴보겠다. 🚀