[Kaggle Gen AI] Day 1 - Transformer 구조 한 눈에 보기🚀
![[Kaggle Gen AI] Day 1 - Transformer 구조 한 눈에 보기🚀](/assets/images/20250402/day1_1.png)
Day 1 인트로 유닛의 팟캐스트에서는
- “LLM은 무엇으로 이루어져 있는가?”
- “어떻게 발전해왔는가?”
- “실제로 어떻게 학습하는가?”
- “그 성능은 어떻게 평가할 수 있을까?”
와 같은 주제들을 중심으로 이야기가 전개된다.
이번 게시물에서는 이 중에서도 LLM의 기반이 되는 트랜스포머 아키텍처에 집중하기로!
트랜스포머는 오늘날 대부분의 최신 LLM들이 공통적으로 기반하고 있는 핵심 구조이자 출발점이라고 합니다.
(The Transformer architecture is the starting point for the foundation of most modern LLMs)
🔧 Transformer란?
이 과정에서 각각의 단어는 Query, Key, Value라는 세 가지 벡터로 변환된다.
- 2017년 Google의 번역 연구 프로젝트에서 시작된 아키텍처
- 처음 제안된 Transformer는Encoder-Decoder 구조로 되어있다
- 한 언어의 문장을 다른 언어로 바꾸는 것처럼작동하는 구조! (like take a sentence in one language and turn it into another language)
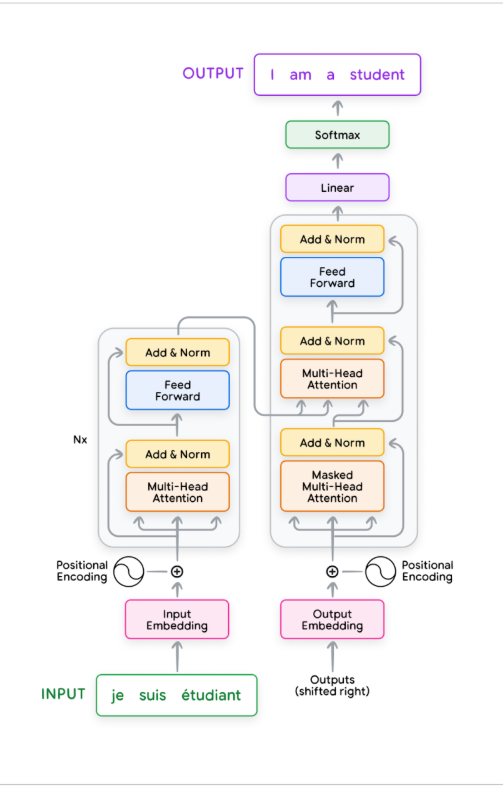 Transformer는 인코더와 디코더 구조로 구성되며, 입력 문장에서 출력 문장을 생성하기까지의 전체 연산 흐름을 포함한다
Transformer는 인코더와 디코더 구조로 구성되며, 입력 문장에서 출력 문장을 생성하기까지의 전체 연산 흐름을 포함한다
Transformer의 구성 요소 간단 정리
- Encoder: 입력 문장 (e.g. 프랑스어)을 받아 의미를 요약한 벡터 표현을 생성
- Decoder: 이 벡터 표현을 바탕으로 출력 문장 (e.g. 영어)을 단어 단위로 생성
- Token 단위 처리: 문장은 “token” 단위로 처리되며, 하나의 단어가 될 수도 있고, 단어의 일부(접두사 등)가 될 수도 있다 (e.g. cat, pre, fix, etc.)
⚙️ Transformer 레이어 내부에서 일어나는 일은?
Transformer 내부에서 입력이 처리되는 과정은 다음과 같다:
-
입력 텍스트를 모델이 이해할 수 있는 형식으로 변환
➡ 먼저 텍스트는 모델이 사용하는 특정 단어 사전(specific vocabulary)을 기반으로 토큰(token)으로 분할된다 -
토큰을 벡터로 변환: 임베딩(Embedding)
➡ 각 토큰은 의미를 담은 고차원 벡터로 바뀌며, 이를 임베딩이라고 한다 -
토큰의 순서를 고려하기 위한 포지셔널 인코딩(Positional Encoding)
➡ 트랜스포머는 모든 토큰을 동시에 병렬로 처리하므로, 단어의 순서 정보가 필요!
이를 위해 포지셔널 인코딩이라는 방식으로 순서를 인코딩한다- 포지셔널 인코딩에는 사인 곡선을 활용한 방식(Sinusoidal Positional Encoding)과 학습 가능한 방식(Learned Positional Encoding)이 있다
- 선택한 방식에 따라서 모델이 긴 문장이나 긴 텍스트 시퀀스를 얼마나 잘 이해하는지에 미묘한 영향을 줄 수 있다
⚠️ 만약 단어의 순서 정보를 주지 않는다면, 마치 단어들이 가방에 들어가 뒤섞이는 것처럼 문장 구조와 의미가 모두 사라질 수 있다. (like throwing all the words in a bag you lose all the structure.)
🔍 Self-Attention과 Multi-Head Attention
Transformer에서 가장 중요한 핵심 개념 중 하나는 바로 Self-Attention이다.
이 메커니즘을 이해하는 데 도움을 주는 대표적인 예시가 바로 “thirsty tiger”:
“The tiger jumped out of a tree to get a drink because it was thirsty.”
이 문장에서 it이 tiger를 지칭한다는 걸 어떻게 알까?
바로 그 역할을 하는 것이 Self-Attention 메커니즘이다.
Self-Attention이란?
Self-Attention은 각 단어가 문장 내 다른 단어들과 어떤 관련이 있는지를 스스로 파악하게 해주는 구조이다.
마치 각 단어가 “이 문장에서 나를 이해하는 데 어떤 단어들이 중요할까?” (“hey, which other words in this sentence are important to understanding me?”) 하고 스스로에게 질문하는 것과 같다.
🔍 Query, Key, Value
이 과정에서 각각의 단어는 Query, Key, Value라는 세 가지 벡터로 변환된다.
- Key: 각 단어가 어떤 정보를 담고 있는지를 나타내는 지표
- Value: 그 단어가 실제로 담고 있는 의미 정보
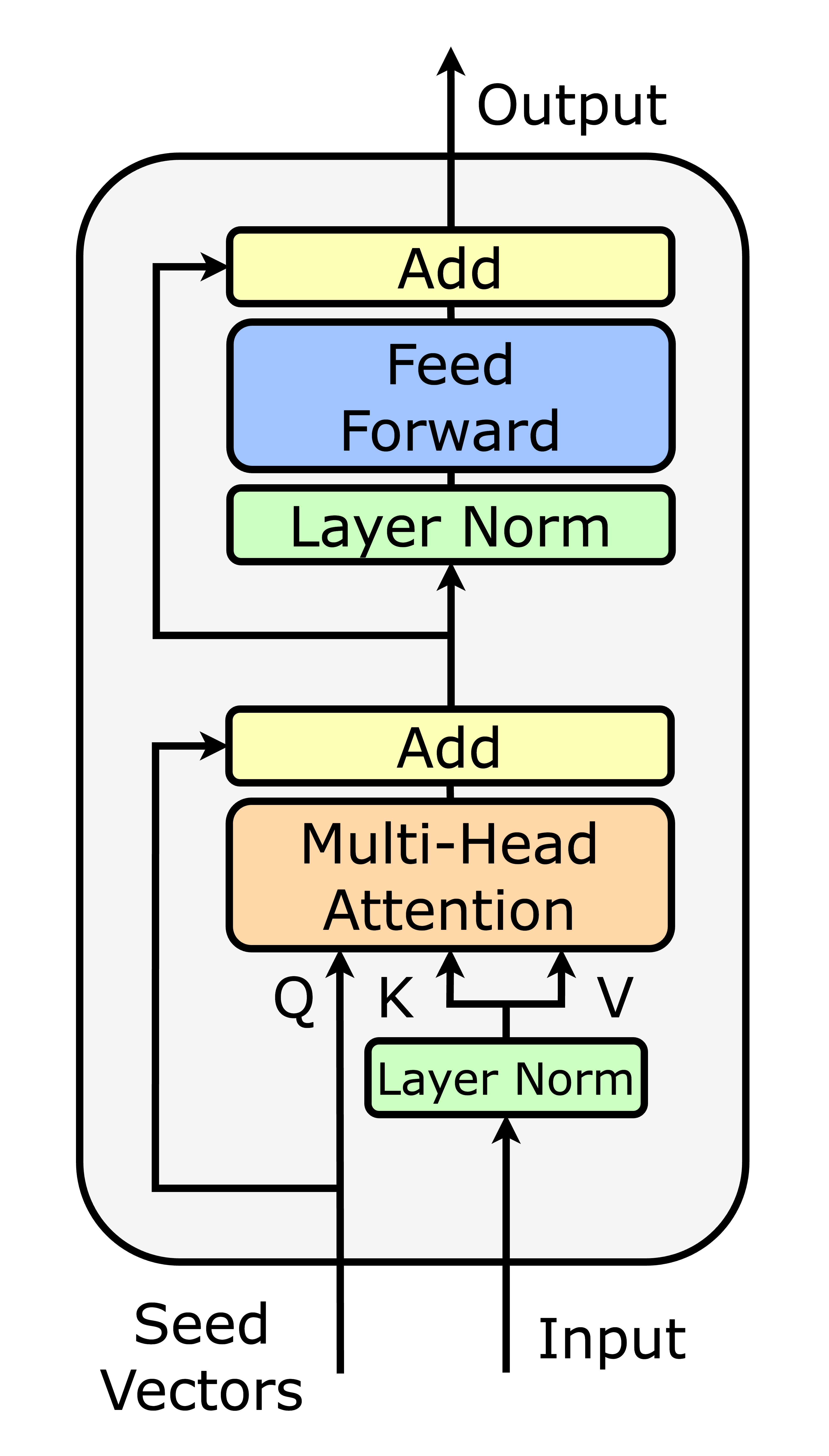
어떻게 작동할까?
각 단어는 문장 내 다른 단어들의 Key를 확인하고, 자신과 가장 유사한 Key를 가진 단어에 더 많은 주의를 기울인다.
e.g. it이라는 단어가 Tiger의 Key와 유사하다는 것을 알게 되면, 모델은 Tiger에 더 집중하여 문맥을 이해하게 된다.
계산은 이렇게!
- 모델은 Query와 다른 단어들의 Key 간 유사도를 계산해 → Attention Score(유사도) 를 얻는다.
- 이 점수는 정규화되어 Attention Weights (가중치) 가 된다.
- 이 가중치를 각 Value 벡터에 곱해 → 가중합(weighted sum)을 계산하면 최종 단어 표현이 된다.
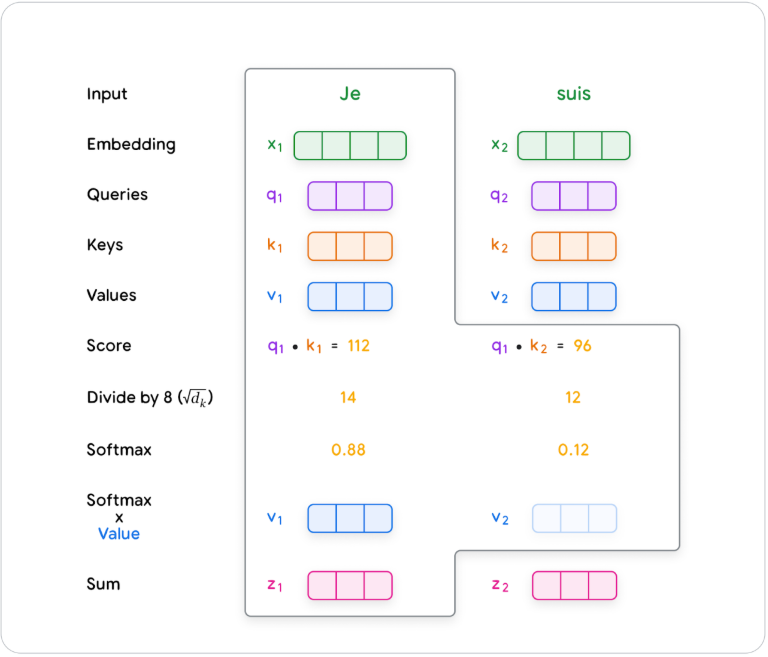 Query와 Key의 내적 → 정규화 → Value에 가중치를 곱해 Attention 출력을 계산하는 전체 흐름
Query와 Key의 내적 → 정규화 → Value에 가중치를 곱해 Attention 출력을 계산하는 전체 흐름
병렬 처리
모든 계산은 단어 하나씩 처리하는 방식이 아니라, 문장 전체의 Query, Key, Value를 각각 하나의 행렬(Q, K, V)로 만들어 병렬로 계산하게 된다. 결과적으로, 각 단어는 자신과 문장 내 다른 단어들 사이의 관계를 반영한 풍부한 벡터 표현을 얻게 된다
기존의 RNN, LSTM같은 순차적 처리 모델들이 어려워했던 장거리 의존성(long-range dependency)도 Transformer에서는 쉽게 다룰 수 있다.
Multi-Head Attention이란?
Self-Attention 메커니즘을 한 번만 수행하는 것이 아니라, 동시에 여러 번 병렬로 수행하는 방식이다. 즉, 같은 문장을 반복해서 바라보되, 각기 다른 시선으로 해석하는 것!
어떻게 다를까?
각 Head는 서로 다른 Query, Key, Value 행렬 세트를 사용한다. 각 Head는 독립적으로 Self-Attention을 수행한다고 볼 수 있다.
e.g. 어떤 Head는 문법적 관계에 집중할 수 있고, 다른 Head는 단어 간 의미적 연결에 더 주의를 기울일 수 있다.
이렇게 서로 다른 관점에서 문장을 해석한 결과를 합쳐서 사용하면, 모델은 문장 전체에 대한 더 깊고 풍부한 이해를 얻게 된다.
🧬 Layer Normalization & Residual Connection
Transformer는 매우 깊은 구조를 가지고 있기 때문에, 학습이 안정적으로 이루어지도록 돕는 두 가지 기술이 매우 중요하다.
1️⃣ Layer Normalization
- 각 층의 활성화 값(activation)의 스케일을 정규화하여 출력값이 지나치게 커지거나 작아지는 걸 방지한다.
- 이렇게 하면 모델이 더 빠르고 안정적으로 학습할 수 있으며, 결과적으로 더 나은 성능을 얻게 된다.
2️⃣ Residual Connection (잔차 연결)
- 입력을 그대로 출력에 더해주는 지름길(shortcut)이다.
- 이 연결 덕분에 원래 입력 정보를 유지한 채로 여러 층을 통과할 수 있다.
- 즉, 모델이 초기 정보나 이전 학습 내용을 “잊지 않고 기억”할 수 있도록 해준다.
- Residual Connection을 사용하면, 신호가 층을 지나며 약해지는 Vanishing Gradient 문제도 줄일 수 있다.
Q. Residual Connection에는 어떤 입력값이 들어가나?
Residual connection은 항상 “직전 레이어의 입력만” 더한다.
즉, 한 레이어의 입력
X를 해당 레이어의 출력에 더해서 다음 레이어로 보내는 방식.
- 레이어를 거치며 정보가 너무 많이 쌓이면, 출력값이 커지고 불안정해질 수 있다.
- 계산량이 늘어나고, 과거 정보에 끌려가는 현상도 생길 수 있고,
- 단순히 입력만 더하는 방식이 계산도 효율적이면서 정보 유지에도 충분히 효과적이라고 함!
Layer Normalization와 Residual Connection는 왜 중요할까?
- Transformer처럼 층이 깊은 모델에서는 이 두 가지 요소가 훈련의 안정성과 성능을 좌우하는 핵심 기법이 된다.
- 특히 Residual Connection은 “과거의 나”를 기억하는 루트처럼 작동해, 깊은 네트워크에서도 중요한 정보가 사라지지 않도록 보장해준다.
🧮 Feed Forward Layer란?
Self-Attention이 끝난 뒤, 각 토큰의 표현은 Feed Forward Neural Network(FFN)을 통해 한 번 더 처리된다.
Feed는 데이터를 순방향(입력→출력)으로 흘려보낸다는 뜻.
(CNN이나 RNN처럼 구조가 복잡하거나 순환하지 않는다.)
어떻게 작동할까?
-
이 레이어는 각 토큰을 독립적으로 처리하며, 토큰 간의 상호작용은 없고 하나의 표현 벡터만을 입력으로 사용한다.
-
일반적으로 다음과 같은 구조로 구성되어 있다:
- 이렇게 하면 모델이 복잡한 함수 표현을 학습할 수 있게 되어, 단순한 Attention만으로는 포착하기 어려운 비선형적인 특징을 잡아낼 수 있다.
📋 정리: Transformer Layer 구성
전체 구조 (Stack of Layers)
1
2
3
4
5
6
7
8
9
10
11
Input
↓
Layer 1
↓
Layer 2
↓
...
↓
Layer N
↓
Output
각 레이어의 구성 (Transformer Encoder 기준)
x
↓
LayerNorm(x)
↓
Multi-Head Self Attention
↓
+Residual Connection (x 더하기)
↓
LayerNorm
↓
Feed Forward Network
↓
+Residual Connection
↓
Output
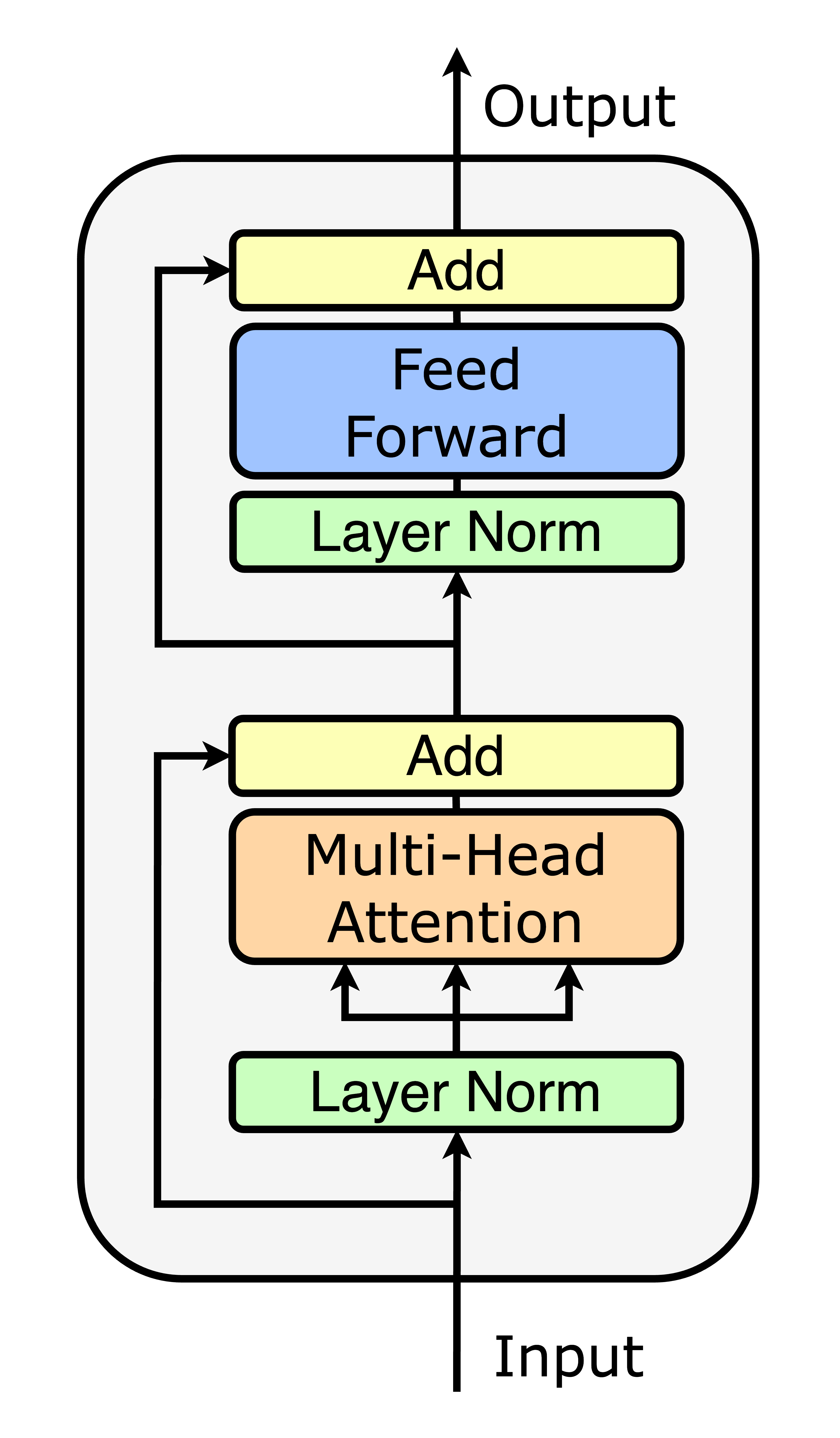
- 하나의 Transformer 레이어는 두 개의 sub-layer로 구성되고,
- 각 sub-layer 앞에는 LayerNorm, 뒤에는 Residual Connection이 적용된다.
- 이 구조를 N번 반복한 것이 전체 Transformer 블록이 된다
💭오늘 챙겨간 것들
이번 게시물에서는 LLM의 뿌리가 되는 Transformer 아키텍처가 왜 그렇게 혁신적이었는지, 그리고 그 안에서 작동하는 Self-Attention과 Multi-Head Attention의 핵심 메커니즘이 무엇인지 이해할 수 있었다!
내일은 이 구조를 바탕으로 GPT같은 최신 LLM들이 사용하는 Decoder-only 아키텍처가 어떻게 작동하는지, 그리고 왜 그런 구조가 선택되었는지에 대해 정리해보겠다.